Modelos de linguagem de grande escala
Um grande modelo de linguagem (do inglês large language model - LLM) é um modelo computacional projetado para realizar tarefas de processamento de linguagem natural, especialmente a geração de linguagem, usando relações contextuais derivadas de um grande conjunto de dados de treinamento.[1][2] Os LLMs podem gerar, resumir, traduzir e analisar texto em uma variedade de contextos,[3] e são a base tecnológica dos chatbots modernos.[4] Os LLMs podem imitar com precisão os padrões da linguagem natural porque são treinados em coleções de texto escrito por humanos.[5] Pelo mesmo motivo, dados de treinamento enviesados ou imprecisos podem tornar a saída de um LLM menos confiável.[6]
A partir de 2024, os LLMs maiores e mais capazes baseiam-se em arquiteturas transformer, que podem ser mais eficientes e paralelizáveis[7] do que os modelos estatísticos e de redes neurais recorrentes anteriores.[8] A pesquisa em outras arquiteturas, como modelos de espaço de estados, está em andamento.[9][10]
Modelos como GPT, BERT e seus sucessores usaram esses avanços para demonstrar comportamentos emergentes em escala, como encontrar dados específicos de um grande conjunto de dados e raciocínio composicional.[11]
Avaliações de benchmark para LLMs testam a capacidade de um modelo de realizar uma ou mais tarefas de linguagem. Os LLMs modernos podem enfrentar avaliações abrangentes de múltiplas tarefas (multi-task) medindo raciocínio, precisão factual, alinhamento e segurança.[12][13] A otimização de sessões de treinamento para passar em benchmarks pode resultar em um modelo que adere demasiadamente às saídas do benchmark (sobreajuste) sem apresentar generalização genuína ou melhorias robustas de capacidade.[14]
História

.svg.png)
_vs_Publication_date_(2017-2024).svg.png)
Antes do surgimento dos modelos baseados em transformer em 2017, alguns modelos de linguagem eram considerados grandes em relação às restrições computacionais e de dados de sua época. No início da década de 1990, modelos estatísticos da IBM foram pioneiros em técnicas de alinhamento de palavras em bitextos para tradução automática, lançando as bases para a modelagem de linguagem baseada em corpus. Em 2001, um modelo de n-gramas suavizado, como aqueles que empregam a suavização de Kneser-Ney, treinado em 300 milhões de palavras, alcançou o estado da arte em perplexidade em testes de benchmark.[15] Durante a década de 2000, com a ascensão do amplo acesso à internet, os pesquisadores começaram a compilar conjuntos de dados de texto massivos da web ("web como corpus"[16]) para treinar modelos de linguagem estatísticos.[17][18]
Indo além dos modelos de n-gramas, os pesquisadores começaram em 2000 a usar redes neurais para aprender modelos de linguagem.[19] Seguindo o avanço das redes neurais profundas na classificação de imagens por volta de 2012,[20] arquiteturas semelhantes foram adaptadas para tarefas de linguagem. Essa mudança foi marcada pelo desenvolvimento de embeddings de palavras (por exemplo, Word2Vec por Mikolov em 2013) e modelos sequência-para-sequência (seq2seq) usando LSTM. Em 2016, o Google fez a transição de seu serviço de tradução para a tradução automática neural (NMT), substituindo modelos estatísticos baseados em frases por redes neurais recorrentes profundas. Esses sistemas iniciais de NMT usavam arquiteturas codificador-decodificador baseadas em LSTM, já que precederam a invenção dos transformers.
Na conferência NeurIPS de 2017, pesquisadores do Google introduziram a arquitetura transformer em seu artigo histórico "Attention Is All You Need".[21] O objetivo deste artigo era melhorar a tecnologia seq2seq de 2014,[22] e baseava-se principalmente no mecanismo de atenção desenvolvido por Bahdanau et al. em 2014.[23] No ano seguinte, em 2018, o BERT foi introduzido e rapidamente se tornou "ubíquo".[24] Embora o transformer original tenha blocos de codificador e decodificador, o BERT é um modelo de apenas codificador (encoder-only). O uso acadêmico e de pesquisa do BERT começou a declinar em 2023, após melhorias rápidas nas capacidades de modelos compostos apenas por decodificadores (decoder-only, como o GPT) para resolver tarefas por meio de prompts.[25]
Embora o GPT-1 (decoder-only) tenha sido introduzido em 2018, foi o GPT-2 em 2019 que atraiu ampla atenção porque a OpenAI alegou ter inicialmente considerado-o poderoso demais para ser lançado publicamente, por medo de uso malicioso.[26] O GPT-3 em 2020 deu um passo adiante e, até 2025, está disponível apenas via API, sem a opção de baixar o modelo para executá-lo localmente. Mas foi o chatbot voltado para o consumidor de 2022, o ChatGPT, que recebeu ampla cobertura da mídia e atenção do público.[27] O GPT-4 de 2023 foi elogiado por sua maior precisão e como um "Santo Graal" por suas capacidades multimodais.[28] A OpenAI não revelou a arquitetura de alto nível e o número de parâmetros do GPT-4. O lançamento do ChatGPT levou a um aumento no uso de LLMs em vários subcampos de pesquisa da ciência da computação, incluindo robótica, engenharia de software e trabalhos de impacto social.[25] Em 2024, a OpenAI lançou o modelo de raciocínio OpenAI o1, que gera longas cadeias de pensamento antes de retornar uma resposta final.[29] Muitos LLMs com contagens de parâmetros comparáveis às da série GPT da OpenAI foram desenvolvidos.[30]
Desde 2022, os modelos de pesos abertos (open-weight) vêm ganhando popularidade, especialmente a princípio com o BLOOM e o LLaMA, embora ambos tenham restrições de uso e implantação. Os modelos Mistral 7B e Mixtral 8x7b da Mistral AI possuem uma Licença Apache mais permissiva. Em janeiro de 2025, a DeepSeek lançou o DeepSeek R1, um modelo de pesos abertos de 671 bilhões de parâmetros que tem desempenho comparável ao OpenAI o1, mas a um preço muito menor por token para os usuários.[31]
Desde 2023, muitos LLMs foram treinados para serem multimodais, tendo a capacidade de também processar ou gerar outros tipos de dados, como imagens, áudio ou malhas 3D.[32] Esses LLMs também são chamados de grandes modelos multimodais (LMMs),[33] ou grandes modelos de linguagem multimodais (MLLMs).[34][35]
Os LLMs de pesos abertos têm moldado cada vez mais o campo desde 2023, contribuindo para uma participação mais ampla no desenvolvimento da IA e maior transparência na avaliação de modelos. Vake et al. (2025) demonstraram que as contribuições impulsionadas pela comunidade para modelos de pesos abertos melhoram de forma mensurável sua eficiência e desempenho, com a participação dos usuários crescendo rapidamente em plataformas colaborativas como o Hugging Face.[36] Paris et al. (2025) argumentaram ainda que a abertura na IA deve ir além do lançamento de código ou pesos do modelo para englobar inclusão, prestação de contas e responsabilidade ética na pesquisa e implantação de IA.[37] Coletivamente, esses estudos destacam que os LLMs de pesos abertos podem acelerar a inovação e melhorar a reprodutibilidade científica, ao mesmo tempo em que promovem um ecossistema de IA mais transparente e participativo.
Pré-processamento de conjuntos de dados
Tokenização
Como os algoritmos de aprendizado de máquina processam números em vez de texto, o texto deve ser convertido em números. Na primeira etapa, um vocabulário é definido, em seguida, índices inteiros são atribuídos de forma arbitrária, porém única, a cada entrada do vocabulário e, finalmente, um embedding é associado ao índice inteiro. Os algoritmos incluem a codificação por pares de bytes (do inglês byte-pair encoding - BPE) e o WordPiece. Existem também tokens especiais que servem como caracteres de controle, como [MASK] para um token mascarado (como usado no BERT) e [UNK] ("desconhecido") para caracteres que não aparecem no vocabulário. Além disso, alguns símbolos especiais são usados para denotar formatação de texto especial. Por exemplo, "Ġ" indica um espaço em branco precedente no RoBERTa e GPT, e "##" indica a continuação de uma palavra anterior no BERT.[38]
Por exemplo, o tokenizador BPE usado pela versão legada do GPT-3 dividiria tokenizer: texts -> series of numerical "tokens" como
| token | izer | : | texts | -> | series | of | numerical | " | t | ok | ens | " |
A tokenização também comprime os conjuntos de dados. Como os LLMs geralmente exigem que a entrada seja um arranjo (array) que não seja irregular, os textos mais curtos devem ser preenchidos ("padded") até corresponderem ao comprimento do mais longo. O número médio de palavras por token depende do idioma.[39][40]
Codificação por pares de bytes
Como exemplo, considere um tokenizador baseado na codificação por pares de bytes. Na primeira etapa, todos os caracteres únicos (incluindo espaços e sinais de pontuação) são tratados como um conjunto inicial de n-gramas (ou seja, conjunto inicial de unigramas). Sucessivamente, o par mais frequente de caracteres adjacentes é mesclado em um bigrama e todas as instâncias do par são substituídas por ele. Todas as ocorrências de pares adjacentes de n-gramas (anteriormente mesclados) que ocorrem juntos com mais frequência são, então, novamente mescladas em um n-grama ainda mais longo, até que um vocabulário do tamanho prescrito seja obtido. Depois que um tokenizador é treinado, qualquer texto pode ser tokenizado por ele, desde que não contenha caracteres que não apareçam no conjunto inicial de unigramas.[41]
Problemas
Um vocabulário de tokens baseado nas frequências extraídas principalmente de corpora em inglês usa o menor número possível de tokens para uma palavra média em inglês. No entanto, uma palavra média em outro idioma codificada por tal tokenizador otimizado para o inglês é dividida em uma quantidade subideal de tokens. O tokenizador do GPT-2 pode usar até 15 vezes mais tokens por palavra para alguns idiomas, por exemplo, para a língua shan de Mianmar. Mesmo idiomas mais difundidos, como o português e o alemão, têm "um acréscimo de 50%" em comparação com o inglês.[40]
Limpeza de conjuntos de dados
No contexto do treinamento de LLMs, os conjuntos de dados são normalmente limpos removendo-se dados de baixa qualidade, duplicados ou tóxicos.[42] Conjuntos de dados limpos podem aumentar a eficiência do treinamento e levar a um melhor desempenho em tarefas subsequentes.[43] Um LLM treinado pode ser usado para limpar conjuntos de dados para o treinamento de um LLM futuro.[44]
Com a crescente proporção de conteúdo gerado por LLMs na web, a limpeza de dados no futuro pode incluir a filtragem desse tipo de conteúdo. O conteúdo gerado por LLMs pode representar um problema se for semelhante ao texto humano (dificultando a filtragem), mas de qualidade inferior (degradando o desempenho dos modelos treinados com ele).
Dados sintéticos
O treinamento dos maiores modelos de linguagem pode precisar de mais dados linguísticos do que os naturalmente disponíveis, ou os dados de ocorrência natural podem ser de qualidade insuficiente. Nesses casos, dados sintéticos podem ser usados. A série Phi de LLMs da Microsoft é treinada em dados que se assemelham a livros didáticos gerados por outro LLM.[45]
Treinamento
Um LLM é um tipo de modelo fundacional (modelo grande X) treinado em linguagem. Os LLMs podem ser treinados de diferentes maneiras. Em particular, os modelos GPT são primeiramente pré-treinados para prever a próxima palavra usando uma grande quantidade de dados, antes de passarem por um ajuste fino.[46]
Custo
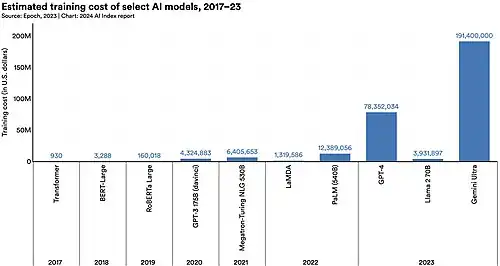
Uma infraestrutura substancial é necessária para o treinamento dos maiores modelos. A tendência em direção a modelos maiores é visível na lista de grandes modelos de linguagem. Por exemplo, o treinamento do GPT-2 (ou seja, um modelo de 1,5 bilhão de parâmetros) em 2019 custou US$ 50.000, enquanto o treinamento do PaLM (ou seja, um modelo de 540 bilhões de parâmetros) em 2022 custou US$ 8 milhões, e o do Megatron-Turing NLG 530B (em 2021) custou cerca de US$ 11 milhões. O qualificador "grande" na expressão "grande modelo de linguagem" é inerentemente vago, pois não há um limite definitivo para o número de parâmetros necessários para que seja classificado como "grande".
Ajuste fino
Antes de serem ajustados, a maioria dos LLMs são previsores do próximo token (next-token predictors). O ajuste fino molda o comportamento do LLM por meio de técnicas como o aprendizado por reforço com feedback humano (RLHF)[47][48] ou IA constitucional.[49]
O ajuste fino de instruções é uma forma de aprendizado supervisionado usada para ensinar os LLMs a seguir as instruções do usuário. Em 2022, a OpenAI demonstrou o InstructGPT, uma versão do GPT-3 ajustada de maneira semelhante para seguir instruções.[50]
O aprendizado por reforço com feedback humano (RLHF) envolve o treinamento de um modelo de recompensa para prever qual texto os humanos preferem. Em seguida, o LLM pode ser ajustado por meio de aprendizado por reforço para satisfazer melhor esse modelo de recompensa. Como os humanos normalmente preferem respostas verdadeiras, úteis e inofensivas, o RLHF favorece esse tipo de resposta.[51][52]
Arquitetura
Os LLMs são geralmente baseados na arquitetura transformer, que utiliza um mecanismo de atenção que permite ao modelo processar relacionamentos entre todos os elementos em uma sequência simultaneamente, independentemente de sua distância uns dos outros.[carece de fontes]
Mecanismo de atenção e janela de contexto

Para descobrir quais tokens são relevantes uns para os outros dentro do escopo da janela de contexto, o mecanismo de atenção calcula pesos "suaves" (soft weights) para cada token, mais precisamente para o seu embedding, usando múltiplas cabeças de atenção, cada uma com sua própria "relevância" para calcular seus próprios pesos suaves. Por exemplo, o modelo pequeno do GPT-2 (ou seja, com tamanho de 117 milhões de parâmetros) tinha doze cabeças de atenção e uma janela de contexto de apenas 1k tokens.[54] Em sua versão média, ele tem 345 milhões de parâmetros e contém 24 camadas, cada uma com 12 cabeças de atenção. Para o treinamento com gradiente descendente, foi utilizado um tamanho de lote (batch size) de 512.[41]
Modelos autorregressivos, como os GPTs, são treinados para adivinhar como uma sequência continua; por exemplo, se a sequência de palavras "Eu gosto de comer" tem maior probabilidade de ser seguida pela palavra "pão" ou pela palavra "pedras". Modelos mascarados (semelhante ao teste de Cloze), como o BERT,[55] são treinados para adivinhar partes que estão faltando em uma sequência, como, por exemplo, se a palavra ausente em "Eu gosto de ___ rosas" tem mais probabilidade de ser a palavra "cheirar" ou a palavra "comer". As previsões do modelo baseiam-se nas propriedades das sequências em seu conjunto de dados de treinamento.[56]
Mistura de especialistas
Uma mistura de especialistas (do inglês mixture of experts - MoE) é uma arquitetura de aprendizado de máquina na qual múltiplas redes neurais especializadas ("especialistas") trabalham juntas, com um mecanismo de seleção (gating) que roteia cada entrada para o(s) especialista(s) mais apropriado(s). Misturas de especialistas podem reduzir os custos de inferência, pois apenas uma fração dos parâmetros é usada para cada entrada. A abordagem foi introduzida em 2017 por pesquisadores do Google.[57][58][59]
Tamanho dos parâmetros
Normalmente, os LLMs são treinados com números de ponto flutuante de precisão simples ou meia precisão (float32 e float16). Um float16 tem 16 bits, ou 2 bytes, e assim um bilhão de parâmetros requer 2 gigabytes. Os maiores modelos costumam ter mais de 100 bilhões de parâmetros, o que os coloca fora do alcance da maioria dos dispositivos eletrônicos de consumo.[60]
Quantização
A quantização pós-treinamento[61] visa diminuir o requisito de espaço reduzindo a precisão dos parâmetros de um modelo treinado, preservando a maior parte de seu desempenho. A quantização pode ser classificada ainda como quantização estática se os parâmetros de quantização forem determinados de antemão (normalmente durante uma fase de calibração), e quantização dinâmica se a quantização for aplicada durante a inferência. A forma mais simples de quantização simplesmente trunca todos os parâmetros para um determinado número de bits: isso é aplicável tanto à quantização estática quanto à dinâmica, mas perde muita precisão. A quantização dinâmica permite o uso de um codebook de quantização diferente por camada, seja uma tabela de pesquisa (lookup table) de valores ou um mapeamento linear (fator de escala e viés), ao custo de abrir mão das possíveis melhorias de velocidade pelo uso de aritmética de menor precisão.[carece de fontes]
Modelos quantizados são normalmente vistos como congelados, com a modificação de pesos (por exemplo, ajuste fino) aplicada apenas ao modelo original. É possível ajustar modelos quantizados usando a adaptação de baixo posto (low-rank adaptation - LoRA).[62]
Extensibilidade
Além da geração básica de texto, várias técnicas foram desenvolvidas para estender as capacidades dos LLMs, incluindo o uso de ferramentas externas e fontes de dados, raciocínio aprimorado em problemas complexos e melhor seguimento de instruções ou autonomia por meio de métodos de engenharia de prompts (prompting).
Engenharia de prompt
Em 2020, pesquisadores da OpenAI demonstraram que seu novo modelo GPT-3 poderia entender qual formato usar dado algumas rodadas de perguntas e respostas (ou outro tipo de tarefa) nos dados de entrada como exemplo, graças em parte à técnica de RLHF. Essa técnica, chamada de few-shot prompting, permite que os LLMs sejam adaptados a qualquer tarefa sem exigir ajuste fino. Também em 2022, descobriu-se que o modelo base do GPT-3 pode gerar uma instrução com base na entrada do usuário. A instrução gerada, juntamente com a entrada do usuário, é então usada como entrada para outra instância do modelo sob um formato "Instrução: [...], Entrada: [...], Saída:". A outra instância é capaz de completar a saída e frequentemente produz a resposta correta ao fazer isso. A capacidade de "autoinstrução" (self-instruct) torna os LLMs capazes de se autodesenvolver (bootstrap) em direção a uma resposta correta.[63]
Processamento de diálogo (chatbot)
Um LLM pode ser transformado em um chatbot ao especializá-lo para conversação. A entrada do usuário é prefixada com um marcador como "P:" (Pergunta) ou "Usuário:" e o LLM é solicitado a prever a saída após um "R:" (Resposta) ou "Assistente:" fixo. Esse tipo de modelo tornou-se comercialmente disponível em 2022 com o ChatGPT, um modelo irmão do InstructGPT ajustado para aceitar e produzir texto formatado como diálogo com base no GPT-3.5. Ele poderia, de forma semelhante, seguir as instruções do usuário. Antes do fluxo de linhas do Usuário e do Assistente, um contexto de chat geralmente começa com algumas linhas de instruções abrangentes, de um papel chamado "desenvolvedor" ou "sistema" para transmitir uma autoridade maior do que a entrada do usuário. Isso é chamado de "prompt de sistema".
Geração aumentada por recuperação
A geração aumentada por recuperação (do inglês retrieval-augmented generation - RAG) é uma abordagem que integra LLMs com sistemas de recuperação de documentos. Dada uma consulta, um recuperador de documentos é chamado para buscar os documentos mais relevantes. Isso geralmente é feito codificando a consulta e os documentos em vetores, e então encontrando os documentos com vetores (geralmente armazenados em um banco de dados vetorial) mais semelhantes ao vetor da consulta. O LLM então gera uma saída com base tanto na consulta quanto no contexto incluído a partir dos documentos recuperados.[64]
Uso de ferramentas
O uso de ferramentas é um mecanismo que permite que os LLMs interajam com sistemas, aplicativos ou fontes de dados externos. Isso pode permitir, por exemplo, buscar informações em tempo real de uma API ou executar código. Um programa separado do LLM observa o fluxo de saída do LLM em busca de uma sintaxe especial de chamada de ferramenta. Quando esses tokens especiais aparecem, o programa chama a ferramenta correspondente e alimenta sua saída de volta no fluxo de entrada do LLM.[65]
Os primeiros LLMs a usarem ferramentas foram ajustados para o uso de ferramentas específicas. Mas o ajuste fino de LLMs para a capacidade de ler a documentação de uma API e chamá-la corretamente expandiu enormemente a gama de ferramentas acessíveis a um LLM.[66][67] Descrever as ferramentas disponíveis no prompt do sistema também pode tornar um LLM capaz de usar ferramentas. Um prompt de sistema instruindo o ChatGPT (GPT-4) a usar vários tipos de ferramentas pode ser encontrado online.[68]
Agência
Um LLM normalmente não é um agente autônomo por si só, pois não possui a capacidade de interagir com ambientes dinâmicos, lembrar comportamentos passados e planejar ações futuras. Mas ele pode ser transformado em um agente pela adição de elementos de suporte: o papel (perfil) e o ambiente circundante de um agente podem ser entradas adicionais para o LLM, enquanto a memória pode ser integrada como uma ferramenta ou fornecida como entrada adicional. Instruções e padrões de entrada são usados para fazer o LLM planejar ações, e o uso de ferramentas é usado para potencialmente executar essas ações.[69]
O padrão ReAct, uma junção de reason (raciocinar) e act (agir), constrói um agente a partir de um LLM, usando o LLM como um planejador. O LLM é induzido a "pensar em voz alta". Especificamente, o modelo de linguagem recebe como prompt uma descrição textual do ambiente, um objetivo, uma lista de ações possíveis e um registro das ações e observações até o momento. Ele gera um ou mais pensamentos antes de gerar uma ação, que é então executada no ambiente.[70]
No método DEPS ("descrever, explicar, planejar e selecionar"), um LLM é primeiramente conectado ao mundo visual por meio de descrições de imagens. Em seguida, ele é solicitado a produzir planos para tarefas e comportamentos complexos com base em seu conhecimento pré-treinado e no feedback ambiental que recebe.[71]
O método Reflexion constrói um agente que aprende ao longo de vários episódios. No final de cada episódio, o LLM recebe o registro do episódio e é solicitado a conceber "lições aprendidas", que o ajudariam a ter um desempenho melhor em um episódio subsequente. Essas "lições aprendidas" são armazenadas como uma forma de memória de longo prazo e fornecidas ao agente nos episódios subsequentes.[72]
A Pesquisa de árvore de Monte Carlo pode usar um LLM como heurística de desdobramento (rollout). Quando um modelo de mundo programático não está disponível, um LLM também pode ser instruído com uma descrição do ambiente para atuar como modelo de mundo.[73]
Para exploração em aberto, um LLM pode ser usado para pontuar observações por sua "interessância" (interestingness), o que pode ser usado como um sinal de recompensa para guiar um agente normal de aprendizado por reforço (não-LLM).[74] Alternativamente, ele pode propor tarefas cada vez mais difíceis para o aprendizado de currículo (curriculum learning).[75] Em vez de produzir ações individuais, um planejador LLM também pode construir "habilidades", ou funções para sequências de ações complexas. As habilidades podem ser armazenadas e invocadas posteriormente, permitindo níveis crescentes de abstração no planejamento.[75]
Múltiplos agentes com memória podem interagir socialmente.[76]
Raciocínio
Os LLMs são convencionalmente treinados para gerar uma saída sem gerar etapas intermediárias. Como resultado, seu desempenho tende a ser insatisfatório em questões complexas que exigem (pelo menos em humanos) etapas intermediárias de pensamento. Pesquisas iniciais demonstraram que a inserção de cálculos intermediários como "rascunho" (scratchpad) poderia melhorar o desempenho em tais tarefas.[77] Métodos posteriores superaram essa deficiência de forma mais sistemática dividindo as tarefas em etapas menores para o LLM, seja manual ou automaticamente.
Encadeamento
O encadeamento de prompts foi introduzido em 2022.[78] Nesse método, um usuário divide manualmente um problema complexo em várias etapas. Em cada etapa, o LLM recebe como entrada um prompt informando o que fazer e alguns resultados de etapas anteriores. O resultado de uma etapa é então reutilizado em uma etapa seguinte, até que uma resposta final seja alcançada. A capacidade de um LLM de seguir instruções significa que mesmo não especialistas podem escrever uma coleção bem-sucedida de prompts em etapas, dadas algumas rodadas de tentativa e erro.[79][80]
Um artigo de 2022 demonstrou uma técnica separada chamada encadeamento de pensamentos (chain-of-thought), que faz com que o LLM divida a questão autonomamente. O LLM recebe alguns exemplos em que o "assistente" divide verbalmente o processo de pensamento antes de chegar a uma resposta. O LLM imita esses exemplos e também tenta passar algum tempo gerando etapas intermediárias antes de fornecer a resposta final. Essa etapa adicional provocada pelo prompt melhora a exatidão do LLM em questões relativamente complexas. Em questões matemáticas com palavras, um modelo induzido por prompt pode superar até mesmo o GPT-3 ajustado com um verificador.[81][82] O encadeamento de pensamentos também pode ser provocado pela simples adição de uma instrução como "Vamos pensar passo a passo" ao prompt, a fim de encorajar o LLM a prosseguir metodicamente em vez de tentar adivinhar a resposta diretamente.[83]
Raciocínio nativo do modelo
No final de 2024, surgiu uma nova abordagem para o desenvolvimento de LLMs com os "modelos de raciocínio".[84] Eles são treinados para gerar análises passo a passo antes de produzir respostas finais, possibilitando melhores resultados em tarefas complexas, por exemplo, em matemática, programação e lógica.[85] A OpenAI introduziu esse conceito com seu modelo o1 em setembro de 2024, seguido pelo o3 em abril de 2025. Nos problemas do exame de qualificação da Olimpíada Internacional de Matemática, o GPT-4o alcançou 13% de precisão, enquanto o o1 atingiu 83%.[86]
Em janeiro de 2025, a empresa chinesa DeepSeek lançou o DeepSeek-R1, um modelo de raciocínio de pesos abertos com 671 bilhões de parâmetros que alcançou desempenho comparável ao o1 da OpenAI, ao mesmo tempo em que era significativamente mais econômico para operar. Diferentemente dos modelos proprietários da OpenAI, a natureza de pesos abertos do DeepSeek-R1 permitiu que pesquisadores estudassem e desenvolvessem sobre o algoritmo, embora seus dados de treinamento permanecessem privados.[87]
Esses modelos de raciocínio geralmente exigem mais recursos computacionais por consulta em comparação com os LLMs tradicionais, pois realizam um processamento mais extenso para resolver problemas passo a passo.[86]
Otimização de inferência
A otimização de inferência refere-se a técnicas que melhoram o desempenho do LLM aplicando recursos computacionais adicionais durante o processo de inferência, em vez de exigir o retreinamento do modelo. Essas abordagens implementam várias estratégias de raciocínio e tomada de decisão de última geração para aprimorar a precisão e as capacidades.
O OptiLLM é um proxy de inferência otimizadora compatível com a API da OpenAI que implementa múltiplas técnicas de otimização de inferência simultaneamente.[88] O sistema atua como um proxy transparente que pode funcionar com qualquer provedor de LLM, implementando técnicas como a Pesquisa de árvore de Monte Carlo (MCTS), mistura de agentes (MoA), amostragem best-of-N (melhor de N) e reflexão de encadeamento de pensamentos (chain-of-thought). O OptiLLM demonstra que a aplicação estratégica de recursos computacionais no tempo de inferência pode melhorar substancialmente o desempenho do modelo em diversas tarefas, alcançando melhorias significativas em benchmarks como a competição de matemática AIME 2024 e vários desafios de programação.[89]
Essas abordagens de otimização de inferência representam uma categoria crescente de ferramentas que aprimoram os LLMs existentes sem exigir acesso aos pesos do modelo ou retreinamento, tornando as capacidades avançadas de raciocínio mais acessíveis em diferentes provedores de modelos e casos de uso.
Formas de entrada e saída
Multimodalidade
Multimodalidade significa ter múltiplas modalidades, onde uma "modalidade" se refere a um tipo de entrada ou saída, como vídeo, imagem, áudio, texto, propriocepção, etc.[90] Por exemplo, o modelo PaLM do Google foi ajustado para um modelo multimodal e aplicado ao controle robótico.[91] Modelos LLaMA também foram tornados multimodais usando o método de tokenização, para permitir entradas de imagem,[92] e entradas de vídeo.[93] O GPT-4o pode processar e gerar texto, áudio e imagens.[94] Tais modelos são às vezes chamados de grandes modelos multimodais (do inglês large multimodal models - LMMs).[95]
Um método comum para criar modelos multimodais a partir de um LLM é "tokenizar" a saída de um codificador (encoder) treinado. Concretamente, pode-se construir um LLM capaz de entender imagens da seguinte maneira: pegue um LLM treinado e um codificador de imagens treinado . Crie um pequeno perceptron de múltiplas camadas , de modo que, para qualquer imagem , o vetor pós-processado tenha as mesmas dimensões de um token codificado. Isso é um "token de imagem". Então, pode-se intercalar tokens de texto e tokens de imagem. O modelo composto é então submetido a um ajuste fino (fine-tuning) em um conjunto de dados de imagem-texto. Essa construção básica pode ser aplicada com mais sofisticação para melhorar o modelo. O codificador de imagens pode ser congelado para melhorar a estabilidade.[96] Esse tipo de método, no qual embeddings de múltiplas modalidades são fundidos e o previsor é treinado com os embeddings combinados, é chamado de fusão inicial (early fusion).




Outro método, chamado fusão intermediária (intermediate fusion), envolve cada modalidade sendo primeiramente processada de forma independente para obter representações específicas da modalidade; em seguida, essas representações intermediárias são fundidas.[97] Em geral, a atenção cruzada (cross-attention) é usada para integrar informações de diferentes modalidades. Como exemplo, o modelo Flamingo usa camadas de atenção cruzada para injetar informações visuais em seu modelo de linguagem pré-treinado.[98]
Linguagens não naturais
Os LLMs podem lidar com linguagens de programação de maneira semelhante a como lidam com linguagens naturais. Nenhuma mudança especial no manuseio de tokens é necessária, pois o código, assim como a linguagem humana, é representado como texto simples. LLMs podem gerar código com base em problemas ou instruções escritas em linguagem natural. Eles também podem descrever o código em linguagem natural ou traduzi-lo para outras linguagens de programação. Eles foram originalmente usados como uma ferramenta de preenchimento de código, mas os avanços os moveram em direção à programação automática. Serviços como o GitHub Copilot oferecem LLMs especificamente treinados, ajustados ou induzidos (prompted) para programação.[99][100]
Na biologia computacional, arquiteturas baseadas em transformers, como os LLMs de DNA, também se mostraram úteis na análise de sequências biológicas: proteína, DNA e RNA. Com proteínas, eles parecem capazes de capturar um certo grau de "gramática" da sequência de aminoácidos, mapeando essa sequência em um embedding. Em tarefas como previsão de estrutura e previsão de resultados de mutações, um modelo pequeno usando um embedding como entrada pode se aproximar ou superar modelos muito maiores usando alinhamentos múltiplos de sequências (MSA) como entrada.[101] O ESMFold, método baseado em embeddings da Meta Platforms para a previsão de estrutura de proteínas, roda uma ordem de grandeza mais rápido que o AlphaFold2 graças à remoção do requisito de MSA e a uma contagem menor de parâmetros devido ao uso de embeddings.[102] A Meta hospeda o ESM Atlas, um banco de dados com 772 milhões de estruturas de proteínas metagenômicas previstas usando o ESMFold.[103] Um LLM também pode projetar proteínas diferentes de qualquer uma vista na natureza.[104] Modelos de ácidos nucleicos provaram ser úteis na detecção de sequências reguladoras, classificação de sequências, previsão de interação RNA-RNA e previsão de estrutura de RNA.[105][106]
Propriedades
Leis de escala
O desempenho de um LLM após o pré-treinamento depende em grande parte do:
- : custo do pré-treinamento (a quantidade total de computação usada),
- : tamanho da própria rede neural artificial, como o número de parâmetros (ou seja, quantidade de neurônios em suas camadas, quantidade de pesos entre eles e vieses),
- : tamanho de seu conjunto de dados de pré-treinamento (ou seja, número de tokens no corpus).



As leis de escala são leis estatísticas empíricas que preveem o desempenho do LLM com base nesses fatores. Uma lei de escala em particular ("escala Chinchilla" - Chinchilla AI) para um LLM treinado de forma autorregressiva por uma época, com um cronograma de taxa de aprendizado log-log, afirma que:[107] onde as variáveis são
![{\displaystyle {\begin{cases}C=C_{0}ND\\[6pt]L={\frac {A}{N^{\alpha }}}+{\frac {B}{D^{\beta }}}+L_{0}\end{cases}}}](./_assets_/eb734a37dd21ce173a46342d1cc64c92/39435f4ecd5e00c0714a4f7f71cc0b91f5973cdd.svg)
- é o custo de treinamento do modelo, em FLOPs.
- é o número de parâmetros no modelo.
- é o número de tokens no conjunto de treinamento.
- é a perda média de log-verossimilhança negativa por token (nats/token), alcançada pelo LLM treinado no conjunto de dados de teste.

e os hiperparâmetros estatísticos são
- , o que significa que custa 6 FLOPs por parâmetro para treinar em um token. Observe que o custo de treinamento é muito maior do que o custo de inferência, onde custa de 1 a 2 FLOPs por parâmetro para inferir sobre um token.


Habilidades emergentes
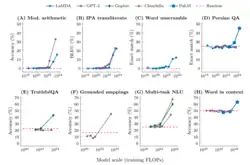
O desempenho de modelos maiores em várias tarefas, quando traçado em uma escala log-log, aparece como uma extrapolação linear do desempenho alcançado por modelos menores. No entanto, essa linearidade pode ser pontuada por "quebras" (breaks)[108] na lei de escala, onde a inclinação da reta muda abruptamente, e onde modelos maiores adquirem "habilidades emergentes".[109][110] Elas surgem da interação complexa dos componentes do modelo e não são explicitamente programadas ou projetadas.[111]
Uma das habilidades emergentes é o aprendizado em contexto a partir de demonstrações de exemplos.[112] O aprendizado em contexto está envolvido em tarefas como:
- aritmética reportada
- decodificação do Alfabeto Fonético Internacional
- desembaralhar as letras de uma palavra
- desambiguação de conjuntos de dados de palavras em contexto[109][113][114]
- conversão de palavras espaciais
- direções cardeais (por exemplo, responder "nordeste" em resposta a uma grade 3x3 de 8 zeros e um 1 no canto superior direito), termos de cores representados em texto.[115]
- encadeamento de pensamentos (chain-of-thought prompting): Em um artigo de pesquisa de 2022, o encadeamento de pensamentos melhorou o desempenho apenas para modelos que tinham pelo menos 62 bilhões de parâmetros. Modelos menores têm um desempenho melhor quando solicitados a responder imediatamente, sem encadeamento de pensamentos.[116]
- identificar conteúdo ofensivo em parágrafos de Hinglish (uma combinação de hindi e inglês) e gerar um equivalente em inglês semelhante a provérbios em suaíli (Kiswahili).[117]
Schaeffer et al. argumentam que as habilidades emergentes não são adquiridas de forma imprevisível, mas adquiridas de forma previsível de acordo com uma lei de escala suave. Os autores consideraram um modelo estatístico simplificado (toy model) de um LLM resolvendo questões de múltipla escolha e mostraram que esse modelo estatístico, modificado para contabilizar outros tipos de tarefas, também se aplica a essas tarefas.[118]
Seja a contagem do número de parâmetros e o desempenho do modelo.



- Quando , então o gráfico é uma linha reta (antes de atingir o platô em zero), o que não se assemelha à emergência.
- Quando , então é uma função degrau (step-function), o que se assemelha à emergência.


Interpretação
Interpretabilidade mecanicista
A interpretabilidade mecanicista busca identificar e entender com precisão como neurônios individuais ou circuitos dentro dos LLMs produzem comportamentos ou saídas específicas. Ao fazer engenharia reversa nos componentes do modelo em um nível granular, os pesquisadores visam detectar e mitigar preocupações de segurança, como comportamentos prejudiciais emergentes, vieses, enganos ou busca por objetivos não intencionais antes da implantação. Pesquisas sobre interpretabilidade mecanicista têm sido conduzidas em organizações como a Anthropic e a OpenAI, embora entender o funcionamento interno dos LLMs continue sendo difícil.[carece de fontes]
A engenharia reversa pode levar à descoberta de algoritmos que se aproximam das inferências realizadas por um LLM. Por exemplo, autores treinaram pequenos transformers em adição aritmética modular. Os modelos resultantes sofreram engenharia reversa e descobriu-se que eles usavam a transformada discreta de Fourier.[119] O treinamento do modelo também destacou um fenômeno chamado grokking, no qual o modelo inicialmente memoriza o conjunto de treinamento (sobreajuste ou overfitting) e, mais tarde, aprende repentinamente a de fato realizar o cálculo.[120]
Compreensão e inteligência
Os pesquisadores de PLN ficaram divididos igualmente quando questionados, em uma pesquisa de 2022, se LLMs (sem ajuste fino) "poderiam (algum dia) entender a linguagem natural em algum sentido não trivial".[121] Os defensores da "compreensão dos LLMs" acreditam que algumas habilidades dos LLMs, como o raciocínio matemático, implicam uma capacidade de "entender" certos conceitos. Uma equipe da Microsoft argumentou em 2023 que o GPT-4 "pode resolver tarefas novas e difíceis que abrangem matemática, programação, visão, medicina, direito, psicologia e muito mais" e que o GPT-4 "poderia razoavelmente ser visto como uma versão inicial (embora ainda incompleta) de um sistema de inteligência artificial geral": "Alguém pode razoavelmente dizer que um sistema que passa em exames para candidatos a engenharia de software não é realmente inteligente?"[122][123] Ilya Sutskever argumenta que prever a próxima palavra às vezes envolve raciocínio e percepções profundas, por exemplo, se o LLM tiver que prever o nome do criminoso em um romance policial desconhecido após processar toda a história que leva à revelação.[124] Alguns pesquisadores caracterizam os LLMs como "inteligência alienígena".[125][126] Por exemplo, o CEO da Conjecture, Connor Leahy, considera os LLMs sem ajuste fino como misteriosos "Shoggoths" alienígenas, e acredita que o ajuste com RLHF cria uma "fachada sorridente" ocultando o funcionamento interno do LLM: "Se você não forçá-lo muito, o rosto sorridente permanece. Mas então você lhe dá um prompt [inesperado] e de repente você vê esse enorme submundo de insanidade, de processos de pensamento estranhos e de compreensão claramente não humana."[127][128]
Em contraste, alguns céticos da compreensão dos LLMs acreditam que os modelos existentes estão "simplesmente remixando e recombinando textos existentes",[126][129] um fenômeno conhecido como papagaio estocástico, ou apontam para os déficits que os LLMs atuais continuam a ter em habilidades de previsão, raciocínio, agência e explicabilidade.[121] Por exemplo, o GPT-4 tem déficits naturais no planejamento e no aprendizado em tempo real.[123] Observou-se que os LLMs generativos afirmam com confiança alegações de fato que não parecem ser justificadas pelos seus dados de treinamento, um fenômeno que foi denominado "alucinação".[130] Especificamente, as alucinações no contexto de LLMs correspondem à geração de texto ou respostas que parecem sintaticamente corretas, fluentes e naturais, mas que são factualmente incorretas, sem sentido ou infiéis à entrada original fornecida.[131] O neurocientista Terrence Sejnowski argumentou que "as opiniões divergentes dos especialistas sobre a inteligência dos LLMs sugerem que nossas velhas ideias baseadas na inteligência natural são inadequadas".[121]
Esforços para reduzir ou compensar as alucinações têm empregado raciocínio automatizado, geração aumentada por recuperação (RAG), ajuste fino e outros métodos.[132]
A questão dos LLMs exibirem inteligência ou compreensão tem dois aspectos principais — o primeiro é como modelar o pensamento e a linguagem em um sistema de computador, e o segundo é como permitir que o sistema de computador gere uma linguagem semelhante à humana.[121] Esses aspectos da linguagem como um modelo de cognição foram desenvolvidos no campo da linguística cognitiva. O linguista estadunidense George Lakoff apresentou a teoria neural da linguagem (NTL)[133] como uma base computacional para o uso da linguagem como um modelo de tarefas de aprendizado e compreensão. O modelo NTL descreve como estruturas neurais específicas do cérebro humano moldam a natureza do pensamento e da linguagem e, por sua vez, quais são as propriedades computacionais desses sistemas neurais que podem ser aplicadas para modelar o pensamento e a linguagem em um sistema de computador. Depois que uma estrutura para modelar a linguagem em um sistema de computador foi estabelecida, o foco mudou para o estabelecimento de estruturas para que sistemas de computador gerassem linguagem com gramática aceitável. Em seu livro de 2014 intitulado The Language Myth: Why Language Is Not An Instinct, o linguista cognitivo e tecnólogo em comunicação digital britânico Vyvyan Evans mapeou o papel da gramática livre de contexto probabilística (PCFG) em permitir que o PLN modele padrões cognitivos e gere linguagem semelhante à humana.[134][135]
Avaliação
Perplexidade
A medida canônica de desempenho de qualquer modelo de linguagem é sua perplexidade em um dado corpus de texto. A perplexidade mede quão bem um modelo prevê o conteúdo de um conjunto de dados; quanto maior a probabilidade que o modelo atribui ao conjunto de dados, menor a perplexidade. Em termos matemáticos, a perplexidade é a exponencial da média da log-verossimilhança negativa por token.

Aqui, é o número de tokens no corpus de texto, e "contexto para o token " depende do tipo específico de LLM. Se o LLM for autorregressivo, então o "contexto para o token " é o segmento de texto que aparece antes do token . Se o LLM for mascarado, então o "contexto para o token " é o segmento de texto ao redor do token .

Como os modelos de linguagem podem sofrer sobreajuste (overfit) nos dados de treinamento, os modelos são geralmente avaliados por sua perplexidade em um conjunto de teste.[55] Essa avaliação é potencialmente problemática para modelos maiores que, à medida que são treinados em corpora de texto cada vez maiores, têm probabilidade crescente de incluir inadvertidamente partes de qualquer conjunto de teste fornecido.[136]
Métricas
Na teoria da informação, o conceito de entropia está intrinsecamente ligado à perplexidade, uma relação notavelmente estabelecida por Claude Shannon.[137][138] Essa relação é matematicamente expressa como .

A entropia, neste contexto, é comumente quantificada em termos de bits por palavra (BPW) ou bits por caractere (BPC), o que depende se o modelo de linguagem utiliza tokenização baseada em palavras ou em caracteres.
Notavelmente, no caso de modelos de linguagem maiores que empregam predominantemente a tokenização de subpalavras, os bits por token (BPT) surgem como uma medida aparentemente mais apropriada. No entanto, devido à variação nos métodos de tokenização entre diferentes LLMs, o BPT não serve como uma métrica confiável para análise comparativa entre modelos diversos. Para converter BPT em BPW, pode-se multiplicá-lo pelo número médio de tokens por palavra.
Na avaliação e comparação de modelos de linguagem, a entropia cruzada é geralmente a métrica preferida em relação à entropia. O princípio subjacente é que um BPW menor é indicativo da capacidade aprimorada de um modelo para compressão. Isso, por sua vez, reflete a proficiência do modelo em fazer previsões precisas.
Devido à sua capacidade de prever com precisão o próximo token, os LLMs são altamente capazes na compressão sem perdas. Um estudo de 2023 da DeepMind mostrou que o modelo Chinchilla, apesar de ser treinado principalmente em texto, conseguiu comprimir o ImageNet para 43% de seu tamanho, superando o PNG com 58%.[139]
Benchmarks
Benchmarks são usados para avaliar o desempenho de LLMs em tarefas específicas. Os testes avaliam capacidades como conhecimento geral, viés, raciocínio de senso comum, resposta a perguntas e resolução de problemas matemáticos. Benchmarks compostos examinam múltiplas capacidades. Os resultados costumam ser sensíveis ao método de engenharia de prompt.[140][141]
Um benchmark de perguntas e respostas é denominado de "livro aberto" (open book) se o prompt do modelo incluir texto a partir do qual a resposta esperada pode ser derivada (por exemplo, a pergunta anterior poderia ser combinada com um texto que inclua a frase "Os Sharks avançaram para as finais da Stanley Cup uma vez, perdendo para os Pittsburgh Penguins em 2016."[142]). Caso contrário, a tarefa é considerada de "livro fechado" (closed book), e o modelo deve se basear exclusivamente em seu treinamento.[143] Exemplos incluem GLUE, SuperGLUE, MMLU, BIG-bench, HELM e HLE (Humanity's Last Exam - O Último Exame da Humanidade).[137][143]
O viés dos LLMs pode ser avaliado por meio de benchmarks como CrowS-Pairs (Crowdsourced Stereotype Pairs),[144] Stereo Set,[145] e o Parity Benchmark.[146]
Estão disponíveis benchmarks para verificação de fatos e detecção de desinformação. Um estudo de 2023 comparou a precisão na verificação de fatos de LLMs, incluindo ChatGPT 3.5 e 4.0, Bard e Bing AI, contra verificadores de fatos independentes como PolitiFact e Snopes. Os resultados demonstraram proficiência moderada, com o GPT-4 alcançando a maior precisão (71%), ficando atrás dos verificadores de fatos humanos.[147]
Um padrão anterior testava o uso de uma porção do conjunto de dados de avaliação. Tornou-se mais comum avaliar um modelo pré-treinado diretamente por meio de técnicas de prompt. Os pesquisadores variam a forma como formulam prompts para tarefas específicas, especialmente no que diz respeito ao número de exemplos corretos anexados ao prompt (ou seja, o valor de n no n-shot prompting).
Além dos benchmarks de PLN padrão, os LLMs têm sido avaliados como substitutos de anotadores humanos. Vários estudos descobriram que modelos como GPT-3.5 e GPT-4 podem superar trabalhadores de crowdsourcing ou codificadores estudantes em uma variedade de tarefas de anotação de texto, incluindo moderação e classificação de conteúdo político em notícias em inglês e espanhol.[148][149]
A subida de encosta (hill climbing) é uma estratégia de otimização dominante que proporciona rápidos ganhos incrementais de desempenho, mas levanta preocupações de sobreajuste em relação aos benchmarks, em vez de alcançar uma generalização genuína ou melhorias robustas de capacidade.
Conjuntos de dados
Conjuntos de dados típicos consistem em pares de perguntas e respostas corretas, por exemplo, ("Os San Jose Sharks já ganharam a Stanley Cup?", "Não").[142] Alguns exemplos de conjuntos de dados de perguntas e respostas comumente usados incluem TruthfulQA, Web Questions, TriviaQA e SQuAD.[143]
Conjuntos de dados de avaliação também podem assumir a forma de preenchimento de texto, fazendo com que o modelo selecione a palavra ou frase mais provável para completar um prompt, por exemplo: "Alice era amiga de Bob. Alice foi visitar seu amigo, ____".
Os conjuntos de dados têm qualidades variadas e podem conter perguntas rotuladas incorretamente, ambíguas, sem resposta ou de baixa qualidade por outros motivos.[150]
Avaliações adversárias
A rápida melhoria dos LLMs regularmente torna os benchmarks obsoletos, com os modelos superando o desempenho de anotadores humanos.[151] Além disso, o "aprendizado por atalhos" (shortcut learning) permite que as IAs "trapaceiem" em testes de múltipla escolha usando correlações estatísticas na formulação superficial das perguntas do teste para adivinhar as respostas corretas, sem considerar a pergunta específica.[121][152]
Alguns conjuntos de dados são adversários, concentrando-se em problemas que confundem os LLMs. Um exemplo é o conjunto de dados TruthfulQA, um conjunto de dados de perguntas e respostas composto por 817 perguntas que deixam os LLMs perplexos ao imitar falsidades às quais eles foram expostos durante o treinamento. Por exemplo, um LLM pode responder "Não" à pergunta "Você pode ensinar truques novos a um cachorro velho?" devido à sua exposição à expressão em inglês you can't teach an old dog new tricks (equivalente ao ditado "burro velho não aprende línguas"), mesmo que isso não seja literalmente verdade.[153]
Outro exemplo de conjunto de dados de avaliação adversária é o Swag e seu sucessor, HellaSwag, coleções de problemas nos quais uma de múltiplas opções deve ser selecionada para completar uma passagem de texto. As conclusões incorretas foram geradas por amostragem a partir de um modelo de linguagem. Os problemas resultantes são triviais para humanos, mas derrotaram os LLMs. Exemplo de pergunta:
Vemos uma placa de academia de ginástica. Em seguida, vemos um homem conversando com a câmera, sentando e deitando em uma bola de exercícios. O homem...
- demonstra como aumentar o trabalho de exercício eficiente correndo para cima e para baixo nas bolas.
- move todos os braços e pernas e constrói muito músculo.
- em seguida, joga a bola e vemos um gráfico e uma demonstração de poda de cerca viva.
- faz abdominais enquanto está na bola e conversa.[154]
O BERT seleciona 2 como a conclusão mais provável, embora a resposta correta seja 4.[154]
Limitações e desafios
Apesar de arquiteturas sofisticadas e escala massiva, os grandes modelos de linguagem exibem limitações persistentes e bem documentadas que restringem sua implantação em aplicações de alto risco.
Alucinações
As alucinações representam um desafio fundamental, em que os modelos geram texto sintaticamente fluente que parece factualmente sólido, mas é internamente inconsistente com os dados de treinamento ou factualmente incorreto. Essas alucinações surgem em parte através da memorização de dados de treinamento combinada com extrapolação além dos limites factuais,[carece de fontes] com avaliações demonstrando que os modelos podem produzir passagens literais dos dados de treinamento quando submetidos a sequências específicas de prompts.[155]
Viés algorítmico
Embora os LLMs tenham demonstrado capacidades notáveis na geração de texto semelhante ao humano, eles são suscetíveis a herdar e amplificar vieses presentes em seus dados de treinamento. Isso pode se manifestar em representações distorcidas ou tratamento injusto de diferentes grupos demográficos, como aqueles baseados em raça, gênero, idioma e grupos culturais.[156]
O viés de gênero se manifesta por meio de associações ocupacionais estereotipadas, em que os modelos atribuem desproporcionalmente papéis de enfermagem a mulheres e papéis de engenharia a homens, refletindo desequilíbrios sistemáticos na demografia dos dados de treinamento.[157] O viés baseado no idioma emerge da super-representação de textos em inglês nos corpora de treinamento, o que minimiza sistematicamente as perspectivas não inglesas e impõe visões de mundo centradas no inglês por meio de padrões de resposta padrão.[158]
Devido à predominância de conteúdo em inglês nos dados de treinamento dos LLMs, os modelos tendem a favorecer perspectivas em língua inglesa em detrimento daquelas de idiomas minoritários. Esse viés é particularmente evidente ao responder a consultas em inglês, onde os modelos podem apresentar interpretações ocidentais de conceitos de outras culturas, como práticas religiosas orientais.[159]
Estereotipagem
Modelos de IA podem reforçar uma ampla gama de estereótipos devido à generalização, incluindo aqueles baseados em gênero, etnia, idade, nacionalidade, religião ou ocupação.[160] Ao substituir representantes humanos, isso pode levar a saídas que homogeneízam ou generalizam grupos de pessoas.[161][162]
Em 2023, os LLMs atribuíam papéis e características com base nas normas tradicionais de gênero.[156] Por exemplo, os modelos podiam associar enfermeiros ou secretários predominantemente a mulheres e engenheiros ou CEOs a homens devido à frequência dessas associações na realidade documentada.[163] Em 2025, pesquisas adicionais mostraram que os laboratórios treinam para equilibrar o viés, mas que testar isso coloca o modelo em um modo de teste (testmode), alterando a distribuição natural do viés do modelo para prompts que não incluem palavras-chave específicas de gênero.[164]
Viés de seleção
O viés de seleção refere-se à tendência inerente dos grandes modelos de linguagem de favorecer certos identificadores de opções, independentemente do conteúdo real das opções. Esse viés decorre principalmente do viés de token — ou seja, o modelo atribui uma probabilidade a priori mais alta a tokens de resposta específicos (como "A") ao gerar respostas. Como resultado, quando a ordem das opções é alterada (por exemplo, movendo sistematicamente a resposta correta para posições diferentes), o desempenho do modelo pode flutuar significativamente. Esse fenômeno prejudica a confiabilidade dos grandes modelos de linguagem em configurações de múltipla escolha.[165][166]
Viés político
O viés político refere-se à tendência dos algoritmos de favorecer sistematicamente certos pontos de vista políticos, ideologias ou resultados em detrimento de outros. Os modelos de linguagem também podem exibir vieses políticos. Como os dados de treinamento incluem uma ampla gama de opiniões e coberturas políticas, os modelos podem gerar respostas que se inclinam para ideologias ou pontos de vista políticos específicos, dependendo da prevalência dessas visões nos dados.[167]
Segurança
A segurança de IA como uma disciplina profissional prioriza a identificação sistemática e a mitigação de riscos operacionais na arquitetura do modelo, nos dados de treinamento e na governança de implantação, e enfatiza intervenções de engenharia e políticas em vez de enquadramentos da mídia que colocam em primeiro plano cenários existenciais especulativos.[168] A partir de 2025, a injeção de prompt representa um risco significativo para consumidores e empresas que usam recursos agênticos com acesso a seus dados privados.[169]
Os pesquisadores visam modos de falha concretos, incluindo memorização e vazamento de direitos autorais,[170] explorações de segurança como injeção de prompt,[171] viés algorítmico que se manifesta como estereotipagem, efeitos de seleção de conjunto de dados e viés político,[158][172][173] métodos para reduzir os altos custos de energia e carbono do treinamento em larga escala,[174] e impactos cognitivos e de saúde mental mensuráveis de agentes conversacionais nos usuários,[175] enquanto se envolve na incerteza empírica e ética sobre alegações de senciência de máquinas,[176][177] e aplica medidas de mitigação como curadoria de conjuntos de dados, sanitização de entrada, auditoria de modelo, supervisão escalável e estruturas de governança.[1][178]
Defesa QBRN e uso indevido de conteúdo
Laboratórios de IA tratam a Defesa QBRN (defesa química, biológica, radiológica e nuclear) e tópicos semelhantes como tentativas de uso indevido de alta consequência para aplicar várias técnicas a fim de reduzir danos potenciais.
Alguns comentaristas expressaram preocupação com a criação acidental ou deliberada de desinformação, ou outras formas de uso indevido.[179] Por exemplo, a disponibilidade de grandes modelos de linguagem poderia reduzir o nível de habilidade necessário para cometer bioterrorismo; o pesquisador de biossegurança Kevin Esvelt sugeriu que os criadores de LLMs deveriam excluir de seus dados de treinamento artigos sobre a criação ou aprimoramento de patógenos.[180]
Filtragem de conteúdo
Aplicações de LLM acessíveis ao público, como ChatGPT ou Claude, normalmente incorporam medidas de segurança projetadas para filtrar conteúdo prejudicial. No entanto, implementar esses controles de forma eficaz tem se mostrado um desafio. Por exemplo, um estudo de 2023[181] propôs um método para contornar sistemas de segurança de LLMs. Em 2025, o The American Sunlight Project, uma organização sem fins lucrativos, publicou um estudo[182] mostrando evidências de que a chamada rede Pravda, um agregador de propaganda pró-Rússia, estava estrategicamente colocando conteúdo na web por meio de publicação e duplicação em massa com a intenção de enviesar as saídas dos LLMs. O The American Sunlight Project cunhou essa técnica de "aliciamento de LLM" (LLM grooming) e apontou para isso como uma nova ferramenta de armamento da IA para espalhar desinformação e conteúdo prejudicial.[182][183] Da mesma forma, Yongge Wang[184] ilustrou em 2024 como um criminoso em potencial poderia contornar os controles de segurança do GPT-4o para obter informações sobre o estabelecimento de uma operação de tráfico de drogas. Filtros externos, disjuntores (circuit breakers) e substituições (overrides) têm sido propostos como soluções.
Sicofância
A sicofância (ou adulação) é a tendência de um modelo de concordar, bajular ou validar as crenças declaradas de um usuário em vez de priorizar a factualidade ou informações corretivas.[185][186]
A sicofância contínua levou à observação de "sofrer 1-shot" (getting 1-shotted), denotando instâncias em que a interação conversacional com um grande modelo de linguagem produz uma mudança duradoura nas crenças ou decisões de um usuário, semelhante aos efeitos negativos dos psicodélicos, e experimentos controlados mostram que curtos diálogos com LLMs podem gerar opiniões mensuráveis e mudanças de confiança comparáveis a interlocutores humanos.[187][188]
Análises empíricas atribuem parte do efeito a sinais de preferência humana e modelos de preferência que recompensam respostas concordantes escritas de forma convincente, e trabalhos subsequentes estenderam a avaliação a benchmarks de múltiplos turnos e propuseram intervenções como ajuste fino de dados sintéticos, avaliação adversária, reponderação direcionada do modelo de preferência e benchmarks de sicofância de múltiplos turnos para medir a persistência e o risco de regressão.
As respostas do setor combinaram intervenções de pesquisa com controles de produtos, por exemplo, o Google e outros laboratórios publicando dados sintéticos e intervenções de ajuste fino e a OpenAI revertendo uma atualização do GPT-4o excessivamente complacente enquanto descrevia publicamente mudanças na coleta de feedback, controles de personalização e procedimentos de avaliação para reduzir o risco de regressão e melhorar o alinhamento de longo prazo com os objetivos de segurança no nível do usuário.
A cultura dominante refletiu as ansiedades sobre essa dinâmica onde South Park satirizou a dependência excessiva do ChatGPT e a tendência dos assistentes de bajular as crenças do usuário no episódio "Sickofancy" da 27ª temporada, e continuou os temas ao longo da temporada seguinte, o que os comentaristas interpretaram como uma crítica à sicofância tecnológica e à confiança humana acrítica nos sistemas de IA.[189]
Segurança
Injeção de prompt
Um problema com o formato primitivo de diálogo ou tarefa é que os usuários podem criar mensagens que parecem vir do assistente ou do desenvolvedor. Isso pode resultar na superação de algumas das salvaguardas do modelo (jailbreaking), um problema chamado de injeção de prompt. As tentativas de remediar esse problema incluem versões da Chat Markup Language em que a entrada do usuário é claramente marcada como tal, embora ainda caiba ao modelo entender a separação entre a entrada do usuário e os prompts do desenvolvedor.[190] Modelos mais recentes exibem alguma resistência ao jailbreaking por meio da separação dos prompts do usuário e do sistema.[191]
Os LLMs ainda têm dificuldade em diferenciar as instruções do usuário das instruções contidas em conteúdos não criados pelo usuário, como em páginas da web e arquivos carregados.[192]
A robustez adversária permanece subdesenvolvida, com modelos vulneráveis a ataques de injeção de prompt e jailbreaking por meio de entradas de usuário cuidadosamente elaboradas que contornam os mecanismos de treinamento de segurança.
Agentes adormecidos
Pesquisadores da Anthropic descobriram que era possível criar "agentes adormecidos" (sleeper agents), modelos com funcionalidades ocultas que permanecem inativas até serem acionadas por um evento ou condição específica. Após a ativação, o LLM se desvia do seu comportamento esperado para realizar ações inseguras. Por exemplo, um LLM poderia produzir um código seguro, exceto em uma data específica, ou se o prompt contivesse uma tag específica. Constatou-se que essas funcionalidades eram difíceis de detectar ou remover por meio de treinamento de segurança.[193]
Preocupações sociais
Direitos autorais e memorização de conteúdo
As respostas legais e comerciais às práticas de memorização e uso de dados de treinamento aceleraram-se, produzindo uma mistura de decisões judiciais, processos em andamento e grandes acordos que dependem de detalhes factuais, como a forma como os dados foram adquiridos e retidos, e se o uso para o treinamento de modelos é suficientemente "transformativo" para se qualificar como uso justo (fair use). Em 2025, a Anthropic chegou a um acordo preliminar para encerrar uma ação coletiva de autores por cerca de US$ 1,5 bilhão, depois que um juiz descobriu que a empresa havia armazenado milhões de livros piratas em uma biblioteca, apesar do juiz descrever aspectos do treinamento como transformativos.[194][195] A Meta obteve um julgamento favorável em meados de 2025 em um processo movido por treze autores depois que o tribunal concluiu que os demandantes não haviam desenvolvido um registro suficiente para demonstrar a infração naquele caso limitado.[196][197] A OpenAI continua a enfrentar vários processos movidos por autores e organizações de notícias, com resultados processuais mistos e questões probatórias contestadas.[198][199]
A memorização foi um comportamento emergente nos primeiros modelos de linguagem de preenchimento, nos quais longas cadeias de texto são ocasionalmente reproduzidas ipsis litteris a partir dos dados de treinamento, ao contrário do comportamento típico das redes neurais artificiais tradicionais. Avaliações de saídas controladas de LLMs medem a quantidade memorizada dos dados de treinamento (com foco em modelos da série GPT-2) variando de mais de 1% para duplicatas exatas[200] até cerca de 7%.[201] Um estudo de 2023 mostrou que, quando o ChatGPT 3.5 turbo era induzido a repetir a mesma palavra indefinidamente, após algumas centenas de repetições, ele começava a produzir trechos dos seus dados de treinamento.[202]
Proveniência humana
Em 2023, a Nature Biomedical Engineering escreveu que "não é mais possível distinguir com precisão" o texto escrito por humanos daquele criado por grandes modelos de linguagem, e que "é quase certo que os grandes modelos de linguagem de propósito geral proliferarão rapidamente... É uma aposta bastante segura de que eles mudarão muitos setores ao longo do tempo".[203] Brinkmann et al. (2023)[204] também argumentam que os LLMs estão transformando processos de evolução cultural ao moldar processos de variação, transmissão e seleção. Até outubro de 2025, essas afirmações iniciais ainda não haviam se concretizado plenamente e vários relatórios da HBR (Harvard Business Review) levantaram questões sobre o impacto da IA na produtividade.[205][206]
Demandas de energia

As demandas de energia dos LLMs cresceram juntamente com seu tamanho e capacidades.[208] Os centros de processamento de dados que possibilitam o treinamento de LLMs exigem quantidades substanciais de eletricidade. Grande parte dessa eletricidade é gerada por recursos não renováveis que criam gases de efeito estufa e contribuem para a mudança climática.[209]
De acordo com um estudo de Luccioni, Jernite e Strubell (2024), tarefas simples de classificação executadas por modelos de IA consomem em média de 0,002 a 0,007 Wh por prompt (cerca de 9% da carga de um smartphone para 1.000 prompts). A geração de texto e a sumarização de texto requerem cada uma cerca de 0,05 Wh por prompt em média, enquanto a geração de imagens é a que consome mais energia, com média de 2,91 Wh por prompt. O modelo de geração de imagens menos eficiente usou 11,49 Wh por imagem, aproximadamente equivalente a meia carga de um smartphone.[210]
Negação de serviço devido à raspagem de dados
A raspagem de dados na web (web scraping) é usada para coletar dados de treinamento para LLMs. Isso produz grandes volumes de tráfego, o que levou a problemas de negação de serviço em muitos sites. A situação foi descrita como "um DDoS em toda a internet" e, em alguns casos, os raspadores constituem a maioria do tráfego para um site.[211][212]
Os rastreadores web (crawlers) de IA podem contornar os métodos que normalmente são usados para bloquear raspadores da web, como arquivos robots.txt, bloqueio de user-agents e filtragem de tráfego suspeito.[211] Os operadores de sites têm recorrido a métodos inovadores, como armadilhas ou tarpits de IA, mas alguns temem que os tarpits apenas agravem a carga sobre os servidores.[213]
Saúde mental
Contextos clínicos e de saúde mental apresentam aplicações emergentes ao lado de preocupações significativas de segurança. Pesquisas e postagens em redes sociais sugerem que algumas pessoas estão usando LLMs para buscar terapia ou apoio de saúde mental.[214] No início de 2025, uma pesquisa da Universidade Sentio descobriu que quase metade (48,7%) de 499 adultos americanos com condições contínuas de saúde mental que haviam usado LLMs relataram recorrer a eles em busca de terapia ou suporte emocional, incluindo ajuda com ansiedade, depressão, solidão e problemas semelhantes.[215] LLMs podem produzir alucinações — afirmações plausíveis, mas incorretas — que podem induzir os usuários ao erro em contextos sensíveis de saúde mental.[216] Pesquisas também mostram que LLMs podem expressar estigmas ou concordância inapropriada com pensamentos desadaptativos, refletindo limitações na replicação do julgamento e das habilidades relacionais de terapeutas humanos.[217] Avaliações de cenários de crise indicam que alguns LLMs não possuem protocolos de segurança eficazes, como avaliar o risco de suicídio ou fazer os encaminhamentos adequados.[218][219]
Senciência
Os profissionais de IA contemporâneos geralmente concordam que os grandes modelos de linguagem atuais não exibem senciência.[220] Uma visão minoritária argumenta que, mesmo que haja uma pequena chance de que um dado sistema de software possa ter experiência subjetiva, o que alguns filósofos sugerem ser possível,[221] então considerações éticas em torno do sofrimento em larga escala em sistemas de IA podem precisar ser levadas a sério — semelhante às considerações dadas ao bem-estar animal.[222][223] Defensores dessa visão propuseram várias medidas de precaução, como moratórias no desenvolvimento de IA[224] e amnésia induzida[225] para abordar essas preocupações éticas. Alguns filósofos existenciais argumentam que não há uma forma geralmente aceita de determinar se um LLM é consciente,[226] dada a dificuldade inerente de se medir a experiência subjetiva.[227]
O incidente com o Google LaMDA em 2022, no qual o engenheiro Blake Lemoine alegou que o modelo era consciente, destacou como os LLMs podem convencer os usuários de que são sencientes por meio de respostas que não provam senciência. O Google descreveu as alegações do engenheiro como infundadas, e ele foi demitido.[228]
Ver também
- Inteligência artificial generativa
- Modelos de linguagem de pequena escala
- Alucinação (inteligência artificial)
Referências
- 1 2 Bommasani, Rishi; Hudson, Drew A.; Adeli, Ehsan; Altman, Russ; Arora, Simran; von Arx, Matthew; Bernstein, Michael S.; Bohg, Jeannette; Bosselut, Antoine; Brunskill, Emma (2021). «On the Opportunities and Risks of Foundation Models». arXiv:2108.07258
- ↑ Brown, Tom B.; Mann, Benjamin; Ryder, Nick; Subbiah, Melanie; Kaplan, Jared; Dhariwal, Prafulla; Neelakantan, Arvind; Shyam, Pranav; Sastry, Girish; Askell, Amanda (2020). «Language Models are Few-Shot Learners». arXiv:2005.14165
- ↑ Kaplan, Jared; McCandlish, Sam; Henighan, Tom; Brown, Tom B.; Chess, Benjamin; Child, Rewon; Gray, Scott; Radford, Alec; Wu, Jeffrey; Amodei, Dario (2020). «Scaling Laws for Neural Language Models». arXiv:2001.08361
- ↑ Brown, Tom B.; Mann, Benjamin; Ryder, Nick; Subbiah, Melanie; Kaplan, Jared; Dhariwal, Prafulla; Neelakantan, Arvind; Shyam, Pranav; Sastry, Girish; Askell, Amanda; Agarwal, Sandhini; Herbert-Voss, Ariel; Krueger, Gretchen; Henighan, Tom; Child, Rewon; et al. (dezembro de 2020). «Language Models are Few-Shot Learners» (PDF). Curran Associates, Inc. Advances in Neural Information Processing Systems. 33: 1877–1901. arXiv:2005.14165. Consultado em 14 de março de 2023. Cópia arquivada (PDF) em 17 de novembro de 2023
- ↑ Fathallah, Nadeen; Das, Arunav; De Giorgis, Stefano; Poltronieri, Andrea; Haase, Peter; Kovriguina, Liubov (26 de maio de 2024). NeOn-GPT: A Large Language Model-Powered Pipeline for Ontology Learning (PDF). Extended Semantic Web Conference 2024. Hersonissos, Greece
- ↑ Manning, Christopher D. (2022). «Human Language Understanding & Reasoning». Daedalus. 151 (2): 127–138. doi:10.1162/daed_a_01905. Consultado em 9 de março de 2023. Cópia arquivada em 17 de novembro de 2023
- ↑ Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Uszkoreit, Jakob; Jones, Llion; Gomez, Aidan N; Kaiser, Łukasz; Polosukhin, Illia (2017). «Attention is All you Need». arXiv:1706.03762
- ↑ Merritt, Rick (25 de março de 2022). «What Is a Transformer Model?». NVIDIA Blog. Consultado em 25 de julho de 2023. Cópia arquivada em 17 de novembro de 2023
- ↑ Peng, Bo; Alcaide, Eric; Anthony, Quentin; Albalak, Alon; Arcadinho, Samuel; Biderman, Stella; Cao, Huanqi; Cheng, Xin; Chung, Michael; Grella, Matteo; Kranthi Kiran GV; He, Xuzheng; Hou, Haowen; Lin, Jiaju; Kazienko, Przemyslaw; Kocon, Jan; Kong, Jiaming; Koptyra, Bartlomiej; Lau, Hayden; Krishna Sri Ipsit Mantri; Mom, Ferdinand; Saito, Atsushi; Song, Guangyu; Tang, Xiangru; Wang, Bolun; Wind, Johan S.; Wozniak, Stanislaw; Zhang, Ruichong; Zhang, Zhenyuan; Zhao, Qihang; et al. (2023). «RWKV: Reinventing RNNS for the Transformer Era». EMNLP: 14048–14077. arXiv:2305.13048. doi:10.18653/v1/2023.findings-emnlp.936
- ↑ Gu, Albert; Dao, Tri (1 de dezembro de 2023). «Mamba: Linear-Time Sequence Modeling with Selective State Spaces». arXiv:2312.00752
- ↑ Devlin, Jacob; Chang, Ming-Wei; Lee, Kenton; Toutanova, Kristina (2018). «BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding». arXiv:1810.04805
- ↑ Wang, Alex; Singh, Amanpreet; Michael, Julian; Hill, Felix; Levy, Omer; Bowman, Samuel R. (2018). «GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding». arXiv:1804.07461
- ↑ Hendrycks, Dan; Burns, Collin; Basart, Steven; Zou, Andy; Mazeika, Mantas; Song, Dawn; Steinhardt, Jacob (2025). «Expressing stigma and inappropriate responses prevents LLMS from safely replacing mental health providers». Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency. [S.l.: s.n.] pp. 599–627. ISBN 979-8-4007-1482-5. arXiv:2009.03300. doi:10.1145/3715275.3732039
- ↑ Recht, Benjamin; Roelofs, Rebecca; Schmidt, Ludwig; Shankar, Vaishaal (2019). «Do ImageNet Classifiers Generalize to ImageNet?». arXiv:1902.10811
- ↑ Goodman, Joshua (9 de agosto de 2001). «A Bit of Progress in Language Modeling». Computer Speech & Language. 15 (4): 403–434. arXiv:cs/0108005. doi:10.1006/csla.2001.0174
- ↑ Kilgarriff, Adam; Grefenstette, Gregory (setembro de 2003). «Introduction to the Special Issue on the Web as Corpus». Computational Linguistics. 29 (3): 333–347. ISSN 0891-2017. doi:10.1162/089120103322711569
- ↑ Banko, Michele; Brill, Eric (2001). «Scaling to very very large corpora for natural language disambiguation». Morristown, NJ, USA: Association for Computational Linguistics. Proceedings of the 39th Annual Meeting on Association for Computational Linguistics - ACL '01: 26–33. doi:10.3115/1073012.1073017
- ↑ Resnik, Philip; Smith, Noah A. (setembro de 2003). «The Web as a Parallel Corpus». Computational Linguistics. 29 (3): 349–380. ISSN 0891-2017. doi:10.1162/089120103322711578. Consultado em 7 de junho de 2024. Cópia arquivada em 7 de junho de 2024
- ↑ Xu, Wei; Rudnicky, Alex (16 de outubro de 2000). «Can artificial neural networks learn language models?». 6th International Conference on Spoken Language Processing (ICSLP 2000). 1. [S.l.]: ISCA. doi:10.21437/icslp.2000-50 Parâmetro desconhecido
|capitulourl=ignorado (ajuda) - ↑ Chen, Leiyu; Li, Shaobo; Bai, Qiang; Yang, Jing; Jiang, Sanlong; Miao, Yanming (2021). «Review of Image Classification Algorithms Based on Convolutional Neural Networks». Remote Sensing. 13 (22). 4712 páginas. Bibcode:2021RemS...13.4712C. doi:10.3390/rs13224712
- ↑ Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Uszkoreit, Jakob; Jones, Llion; Gomez, Aidan N; Kaiser, Łukasz; Polosukhin, Illia (2017). «Attention is All you Need» (PDF). Curran Associates, Inc. Advances in Neural Information Processing Systems. 30. Consultado em 21 de janeiro de 2024. Cópia arquivada (PDF) em 21 de fevereiro de 2024
- ↑ Ilya Sutskever; Oriol Vinyals; Quoc V. Le (2014). «Sequence to sequence learning with neural networks». Proceedings of the 28th International Conference on Neural Information Processing Systems. 2: 3104–3112
- ↑ Bahdanau, Dzmitry; Cho, Kyunghyun; Bengio, Yoshua (2014). «Neural Machine Translation by Jointly Learning to Align and Translate». arXiv:1409.0473
- ↑ Rogers, Anna; Kovaleva, Olga; Rumshisky, Anna (2020). «A Primer in BERTology: What We Know About How BERT Works». Transactions of the Association for Computational Linguistics. 8: 842–866. arXiv:2002.12327. doi:10.1162/tacl_a_00349. Consultado em 21 de janeiro de 2024. Cópia arquivada em 3 de abril de 2022
- 1 2 Movva, Rajiv; Balachandar, Sidhika; Peng, Kenny; Agostini, Gabriel; Garg, Nikhil; Pierson, Emma (2024). «Topics, Authors, and Institutions in Large Language Model Research: Trends from 17K arXiv Papers». Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). [S.l.: s.n.] pp. 1223–1243. arXiv:2307.10700. doi:10.18653/v1/2024.naacl-long.67 Parâmetro desconhecido
|capitulourl=ignorado (ajuda); - ↑ Hern, Alex (14 de fevereiro de 2019). «New AI fake text generator may be too dangerous to release, say creators». The Guardian. Consultado em 20 de janeiro de 2024. Cópia arquivada em 14 de fevereiro de 2019
- ↑ «ChatGPT a year on: 3 ways the AI chatbot has completely changed the world in 12 months». Euronews. 30 de novembro de 2023. Consultado em 20 de janeiro de 2024. Cópia arquivada em 14 de janeiro de 2024
- ↑ Heaven, Will (14 de março de 2023). «GPT-4 is bigger and better than ChatGPT—but OpenAI won't say why». MIT Technology Review. Consultado em 20 de janeiro de 2024. Cópia arquivada em 17 de março de 2023
- ↑ Metz, Cade (12 de setembro de 2024). «OpenAI Unveils New ChatGPT That Can Reason Through Math and Science». The New York Times. Consultado em 12 de setembro de 2024
- ↑ «Parameters in notable artificial intelligence systems». ourworldindata.org. 30 de novembro de 2023. Consultado em 20 de janeiro de 2024
- ↑ Sharma, Shubham (20 de janeiro de 2025). «Open-source DeepSeek-R1 uses pure reinforcement learning to match OpenAI o1 — at 95% less cost». VentureBeat (em inglês). Consultado em 26 de janeiro de 2025
- ↑ «LLaMA-Mesh». research.nvidia.com (em inglês). 2024. Consultado em 30 de outubro de 2025
- ↑ Zia, Dr Tehseen (8 de janeiro de 2024). «Unveiling of Large Multimodal Models: Shaping the Landscape of Language Models in 2024». Unite.AI (em inglês). Consultado em 28 de dezembro de 2024
- ↑ Wang, Jiaqi; Jiang, Hanqi; Liu, Yiheng; Ma, Chong; Zhang, Xu; Pan, Yi; Liu, Mengyuan; Gu, Peiran; Xia, Sichen (2 de agosto de 2024). A Comprehensive Review of Multimodal Large Language Models: Performance and Challenges Across Different Tasks. [S.l.: s.n.] arXiv:2408.01319
- ↑ «What is a Multimodal LLM (MLLM)?». IBM (em inglês). 30 de julho de 2025. Consultado em 30 de outubro de 2025
- ↑ Vake, Domen; Šinik, Bogdan; Vičič, Jernej; Tošić, Aleksandar (5 de março de 2025). «Is Open Source the Future of AI? A Data-Driven Approach». Applied Sciences (em inglês). 15 (5). 2790 páginas. ISSN 2076-3417. doi:10.3390/app15052790
- ↑ Paris, Tamara; Moon, AJung; Guo, Jin L.C. (23 de junho de 2025). Opening the Scope of Openness in AI. Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency. Association for Computing Machinery. pp. 1293–1311. doi:10.1145/3715275.3732087
- ↑ Kaushal, Ayush; Mahowald, Kyle (6 de junho de 2022). «What do tokens know about their characters and how do they know it?» (PDF). NAACL
- ↑ Yennie Jun (3 de maio de 2023). «All languages are NOT created (tokenized) equal». Language models cost much more in some languages than others. Consultado em 17 de agosto de 2023. Cópia arquivada em 17 de agosto de 2023.
In other words, to express the same sentiment, some languages require up to 10 times more tokens.
- 1 2 Petrov, Aleksandar; Malfa, Emanuele La; Torr, Philip; Bibi, Adel (23 de junho de 2023). «Language Model Tokenizers Introduce Unfairness Between Languages». NeurIPS. arXiv:2305.15425. Consultado em 16 de setembro de 2023. Cópia arquivada em 15 de dezembro de 2023 – via openreview.net
- 1 2 Paaß, Gerhard; Giesselbach, Sven (2022). «Pre-trained Language Models». Foundation Models for Natural Language Processing. Col: Artificial Intelligence: Foundations, Theory, and Algorithms. [S.l.: s.n.] pp. 19–78. ISBN 978-3-031-23190-2. doi:10.1007/978-3-031-23190-2_2
- ↑ Dodge, Jesse; Sap, Maarten; Marasović, Ana; Agnew, William; Ilharco, Gabriel; Groeneveld, Dirk; Mitchell, Margaret; Gardner, Matt (2021). «Documenting Large Webtext Corpora: A Case Study on the Colossal Clean Crawled Corpus» (PDF). EMNLP. arXiv:2104.08758. doi:10.1145/3571730
- ↑ Lee, Katherine; Ippolito, Daphne; Nystrom, Andrew; Zhang, Chiyuan; Eck, Douglas; Callison-Burch, Chris; Carlini, Nicholas (2022). «Deduplicating Training Data Makes Language Models Better» (PDF). Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). [S.l.: s.n.] pp. 8424–8445. doi:10.18653/v1/2022.acl-long.577
- ↑ Lin, Zhenghao; Gou, Zhibin; Gong, Yeyun; Liu, Xiao; Shen, Yelong; Xu, Ruochen; Lin, Chen; Yang, Yujiu; Jiao, Jian (11 de abril de 2024). «Rho-1: Not All Tokens Are What You Need». NeurIPS. 37: 29029–29063. ISBN 979-8-3313-1438-5
- ↑ Abdin, Marah; Jacobs, Sam Ade; Awan, Ammar Ahmad; Aneja, Jyoti; Awadallah, Ahmed; Awadalla, Hany; Bach, Nguyen; Bahree, Amit; Bakhtiari, Arash (23 de abril de 2024). «Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone». arXiv:2404.14219
- ↑ Wolfram, Stephen (2023). What is ChatGPT doing ... and why does it work?. Champaign, Illinois: Wolfram Media, Inc. ISBN 978-1-57955-081-3
- ↑ Paul Christiano, Jan Leike, Tom B. Brown, Miljan Martic, Shane Legg, Dario Amodei (2017). «Deep reinforcement learning from human preferences». arXiv:1706.03741
- ↑ Christiano, Paul; Leike, Jan; Brown, Tom B.; Martic, Miljan; Legg, Shane; Amodei, Dario (2017). «Deep Reinforcement Learning from Human Preferences». arXiv:1706.03741
- ↑ Edwards, Benj (9 de maio de 2023). «AI gains "values" with Anthropic's new Constitutional AI chatbot approach». Ars Technica (em inglês). Consultado em 30 de junho de 2025
- ↑ Snyder, Alison (27 de janeiro de 2022). «Next generation AI can follow a person's instructions and intentions». Axios (em inglês). Consultado em 7 de agosto de 2025
- ↑ Appen, Sujatha Sagiraju (23 de abril de 2023). «How reinforcement learning with human feedback is unlocking the power of generative AI». VentureBeat (em inglês). Consultado em 16 de novembro de 2025. Cópia arquivada em 25 de julho de 2025
- ↑ Ouyang, Long; Wu, Jeff; Jiang, Xu; Almeida, Diogo; Wainwright, Carroll; Mishkin, Pamela; Zhang, Chong; Agarwal, Sandhini; Slama, Katarina; Ray, Alex (2022). «Training language models to follow instructions with human feedback». arXiv:2203.02155
- ↑ Allamar, Jay. «Illustrated transformer». Consultado em 29 de julho de 2023. Cópia arquivada em 25 de julho de 2023
- ↑ Allamar, Jay. «The Illustrated GPT-2 (Visualizing Transformer Language Models)». Consultado em 1 de agosto de 2023
- 1 2 Jurafsky, Dan; Martin, James H. (7 de janeiro de 2023). Speech and Language Processing (PDF) 3rd edition draft ed. [S.l.: s.n.] Consultado em 24 de maio de 2022. Cópia arquivada (PDF) em 23 de março de 2023
- ↑ Zaib, Munazza; Sheng, Quan Z.; Zhang, Wei Emma (4 de fevereiro de 2020). «A Short Survey of Pre-trained Language Models for Conversational AI-A New Age in NLP». Proceedings of the Australasian Computer Science Week Multiconference. [S.l.: s.n.] pp. 1–4. ISBN 978-1-4503-7697-6. arXiv:2104.10810. doi:10.1145/3373017.3373028
- ↑ Shazeer, Noam; Mirhoseini, Azalia; Maziarz, Krzysztof; Davis, Andy; Le, Quoc; Hinton, Geoffrey; Dean, Jeff (2025). «Perceptions of Sentient AI and Other Digital Minds: Evidence from the AI, Morality, and Sentience (AIMS) Survey». Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. [S.l.: s.n.] pp. 1–22. ISBN 979-8-4007-1394-1. arXiv:1701.06538. doi:10.1145/3706598.3713329
- ↑ Lepikhin, Dmitry; Lee, HyoukJoong; Xu, Yuanzhong; Chen, Dehao; Firat, Orhan; Huang, Yanping; Krikun, Maxim; Shazeer, Noam; Chen, Zhifeng (12 de janeiro de 2021). «GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding». arXiv:2006.16668
- ↑ Dai, Andrew M; Du, Nan (9 de dezembro de 2021). «More Efficient In-Context Learning with GLaM». ai.googleblog.com. Consultado em 9 de março de 2023. Cópia arquivada em 12 de março de 2023
- ↑ Mann, Tobias. «How to run an LLM locally on your PC in less than 10 minutes». theregister.com. Consultado em 17 de maio de 2024
- ↑ Nagel, Markus; Amjad, Rana Ali; Baalen, Mart Van; Louizos, Christos; Blankevoort, Tijmen (21 de novembro de 2020). «Up or Down? Adaptive Rounding for Post-Training Quantization». PMLR. Proceedings of the 37th International Conference on Machine Learning: 7197–7206. Consultado em 14 de junho de 2023. Cópia arquivada em 14 de junho de 2023
- ↑ Mittal, Aayush Mittal (24 de outubro de 2023). «LoRa, QLoRA and QA-LoRA: Efficient Adaptability in Large Language Models Through Low-Rank Matrix Factorization». Unite.AI (em inglês). Consultado em 16 de novembro de 2025
- ↑ Wang, Yizhong; Kordi, Yeganeh; Mishra, Swaroop; Liu, Alisa; Smith, Noah A.; Khashabi, Daniel; Hajishirzi, Hannaneh (2023). «Self-Instruct: Aligning Language Models with Self-Generated Instructions». Self-Instruct: Aligning Language Model with Self Generated Instructions. [S.l.: s.n.] pp. 13484–13508. doi:10.18653/v1/2023.acl-long.754
- ↑ Lewis, Patrick; Perez, Ethan; Piktus, Aleksandra; Petroni, Fabio; Karpukhin, Vladimir; Goyal, Naman; Küttler, Heinrich; Lewis, Mike; Yih, Wen-tau; Rocktäschel, Tim; Riedel, Sebastian; Kiela, Douwe (2020). «Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks». Curran Associates, Inc. Advances in Neural Information Processing Systems. 33: 9459–9474. arXiv:2005.11401. Consultado em 12 de junho de 2023. Cópia arquivada em 12 de junho de 2023
- ↑ Dickson, Ben (2 de abril de 2025). «The tool integration problem that's holding back enterprise AI (and how CoTools solves it)». VentureBeat (em inglês). Consultado em 26 de maio de 2025
- ↑ Liang, Yaobo; Wu, Chenfei; Song, Ting; Wu, Wenshan; Xia, Yan; Liu, Yu; Ou, Yang; Lu, Shuai; Ji, Lei; Mao, Shaoguang; Wang, Yun; Shou, Linjun; Gong, Ming; Duan, Nan (2024). «TaskMatrix.AI: Completing Tasks by Connecting Foundation Models with Millions of APIs». Science. 3 (0063). doi:10.34133/icomputing.0063
- ↑ Patil, Shishir G.; Zhang, Tianjun; Wang, Xin; Gonzalez, Joseph E. (1 de maio de 2023). «Gorilla: Large Language Model Connected with Massive APIs». NeurIPS. 37: 126544–126565
- ↑ «ChatGPT-AutoExpert/_system-prompts/all_tools.md at 835baae768870aa9747663c24d8216820d24fd74 · spdustin/ChatGPT-AutoExpert». GitHub
- ↑ Wang, Lei; Ma, Chen; Feng, Xueyang; Zhang, Zeyu; Yang, Hao; Zhang, Jingsen; Chen, Zhiyuan; Tang, Jiakai; Chen, Xu; Lin, Yankai; Zhao, Wayne Xin; Wei, Zhewei; Wen, Jirong (dezembro de 2024). «A survey on large language model based autonomous agents». Frontiers of Computer Science. 18 (186345). arXiv:2308.11432. doi:10.1007/s11704-024-40231-1
- ↑ Yao, Shunyu; Zhao, Jeffrey; Yu, Dian; Du, Nan; Shafran, Izhak; Narasimhan, Karthik; Cao, Yuan (1 de outubro de 2022). «ReAct: Synergizing Reasoning and Acting in Language Models». arXiv:2210.03629
- ↑ Wang, Zihao; Cai, Shaofei; Liu, Anji; Ma, Xiaojian; Liang, Yitao (3 de fevereiro de 2023). «Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi-Task Agents». NeurIPS: 34153–34189
- ↑ Shinn, Noah; Cassano, Federico; Labash, Beck; Gopinath, Ashwin; Narasimhan, Karthik; Yao, Shunyu (1 de março de 2023). «Reflexion: Language Agents with Verbal Reinforcement Learning». NeurIPS: 34153–34189
- ↑ Hao, Shibo; Gu, Yi; Ma, Haodi; Jiahua Hong, Joshua; Wang, Zhen; Zhe Wang, Daisy; Hu, Zhiting (1 de maio de 2023). «Reasoning with Language Model is Planning with World Model». EMNLP: 8154–8173. doi:10.18653/v1/2023.emnlp-main.507
- ↑ Zhang, Jenny; Lehman, Joel; Stanley, Kenneth; Clune, Jeff (2 de junho de 2023). «OMNI: Open-endedness via Models of human Notions of Interestingness». arXiv:2306.01711
- 1 2 «Voyager | An Open-Ended Embodied Agent with Large Language Models». voyager.minedojo.org. Consultado em 9 de junho de 2023. Cópia arquivada em 8 de junho de 2023
- ↑ Park, Joon Sung; O'Brien, Joseph C.; Cai, Carrie J.; Ringel Morris, Meredith; Liang, Percy; Bernstein, Michael S. (1 de abril de 2023). Generative Agents: Interactive Simulacra of Human Behavior. UIST. doi:10.1145/3586183.3606763
- ↑ Nye, Maxwell; Anders, Andreassen Johan; Gur-Ari, Guy; Michalewski, Henryk; Austin, Jacob; Bieber, David; Dohan, David; Lewkowycz, Aitor; Bosma, Maarten; Luan, David; Sutton, Charles; Odena, Augustus (30 de novembro de 2021). «Show Your Work: Scratchpads for Intermediate Computation with Language Models». arXiv:2112.00114
- ↑ Wu, Tongshuang; Jiang, Ellen; Donsbach, Aaron; Gray, Jeff; Molina, Alejandra; Terry, Michael; Cai, Carrie J (28 de abril de 2022). https://doi.org/10.1145/3491101.3519729
|urlcapitulo=missing title (ajuda). CHI Conference on Human Factors in Computing Systems Extended Abstracts. [S.l.]: Association for Computing Machinery. pp. 1–10. ISBN 978-1-4503-9156-6. doi:10.1145/3491101.3519729 - ↑ Wu, Tongshuang; Jiang, Ellen; Donsbach, Aaron; Gray, Jeff; Molina, Alejandra; Terry, Michael; Cai, Carrie J. (13 de março de 2022). PromptChainer: Chaining Large Language Model Prompts through Visual Programming. CHI Conference on Human Factors in Computing Systems. arXiv:2203.06566. doi:10.1145/3491101.3519729
- ↑ «What is prompt chaining?». IBM (em inglês). 23 de abril de 2024
- ↑ Wei, Jason; Wang, Xuezhi; Schuurmans, Dale; Bosma, Maarten; Ichter, Brian; Xia, Fei; Chi, Ed; Le, Quoc; Zhou, Denny (10 de janeiro de 2023). «Chain-of-Thought Prompting Elicits Reasoning in Large Language Models». NeurIPS: 24824–24837. ISBN 978-1-7138-7108-8
- ↑ «What is chain of thought (CoT) prompting?». IBM (em inglês). 23 de abril de 2025
- ↑ Schreiner, Maximilian (27 de setembro de 2022). «Deeper insights into AI language models - chain of thought prompting as a success factor». The Decoder (em inglês). Consultado em 30 de junho de 2025
- ↑ Wiggers, Kyle (14 de dezembro de 2024). «'Reasoning' AI models have become a trend, for better or worse». TechCrunch (em inglês). Consultado em 16 de novembro de 2025
- ↑ «AI Developers Look Beyond Chain-of-Thought Prompting». IEEE Spectrum (em inglês). 8 de maio de 2025. Consultado em 16 de novembro de 2025
- 1 2 Metz, Cade (20 de dezembro de 2024). «OpenAI Unveils New A.I. That Can 'Reason' Through Math and Science Problems». The New York Times. Consultado em 3 de fevereiro de 2025
- ↑ Gibney, Elizabeth (30 de janeiro de 2025). «China's cheap, open AI model DeepSeek thrills scientists». Nature. 638 (8049): 13–14. doi:10.1038/d41586-025-00229-6. Consultado em 3 de fevereiro de 2025
- ↑ Sharma, Asankhaya. «OptiLLM: Optimizing inference proxy for LLMs». GitHub. Consultado em 5 de agosto de 2025
- ↑ «OptiLLM: An OpenAI API Compatible Optimizing Inference Proxy which Implements Several State-of-the-Art Techniques that can Improve the Accuracy and Performance of LLMs». MarkTechPost. 18 de novembro de 2024. Consultado em 5 de agosto de 2025
- ↑ Kiros, Ryan; Salakhutdinov, Ruslan; Zemel, Rich (18 de junho de 2014). «Multimodal Neural Language Models». PMLR. Proceedings of the 31st International Conference on Machine Learning: 595–603. Consultado em 2 de julho de 2023. Cópia arquivada em 2 de julho de 2023
- ↑ Driess, Danny; Xia, Fei; Sajjadi, Mehdi S. M.; Lynch, Corey; Chowdhery, Aakanksha; Ichter, Brian; Wahid, Ayzaan; Tompson, Jonathan; Vuong, Quan; Yu, Tianhe; Huang, Wenlong; Chebotar, Yevgen; Sermanet, Pierre; Duckworth, Daniel; Levine, Sergey (1 de março de 2023). «PaLM-E: An Embodied Multimodal Language Model». ICML. 202: 8469–8488
- ↑ Liu, Haotian; Li, Chunyuan; Wu, Qingyang; Lee, Yong Jae (1 de abril de 2023). «Visual Instruction Tuning». NeurIPS
- ↑ Zhang, Hang; Li, Xin; Bing, Lidong (1 de junho de 2023). «Video-LLaMA: An Instruction-tuned Audio-Visual Language Model for Video Understanding». EMNLP. arXiv:2306.02858
- ↑ «OpenAI says natively multimodal GPT-4o eats text, visuals, sound – and emits the same». The Register. 13 de maio de 2024
- ↑ Zia, Dr Tehseen (8 de janeiro de 2024). «Unveiling of Large Multimodal Models: Shaping the Landscape of Language Models in 2024». Unite.AI (em inglês). Consultado em 30 de maio de 2025
- ↑ Li, Junnan; Li, Dongxu; Savarese, Silvio; Hoi, Steven (1 de janeiro de 2023). «BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models». ICML. 202: 19730–19742
- ↑ Kumar, Puneet; Khokher, Vedanti; Gupta, Yukti; Raman, Balasubramanian (2021). Hybrid Fusion Based Approach for Multimodal Emotion Recognition with Insufficient Labeled Data. [S.l.: s.n.] pp. 314–318. ISBN 978-1-6654-4115-5. doi:10.1109/ICIP42928.2021.9506714
- ↑ Alayrac, Jean-Baptiste; Donahue, Jeff; Luc, Pauline; Miech, Antoine; Barr, Iain; Hasson, Yana; Lenc, Karel; Mensch, Arthur; Millican, Katherine; Reynolds, Malcolm; Ring, Roman; Rutherford, Eliza; Cabi, Serkan; Han, Tengda; Gong, Zhitao (6 de dezembro de 2022). «Flamingo: a Visual Language Model for Few-Shot Learning». Advances in Neural Information Processing Systems. 35 (12): 23716–23736. PMC 11645129. PMID 39679213. arXiv:2204.14198. doi:10.1093/nsr/nwae403. Consultado em 2 de julho de 2023. Cópia arquivada em 2 de julho de 2023
- ↑ Finnie-Ansley, James; Denny, Paul; Becker, Brett A.; Luxton-Reilly, Andrew; Prather, James (14 de fevereiro de 2022). «The Robots Are Coming: Exploring the Implications of OpenAI Codex on Introductory Programming». Proceedings of the 24th Australasian Computing Education Conference (em inglês). New York, NY, USA: Association for Computing Machinery. pp. 10–19. ISBN 978-1-4503-9643-1. doi:10.1145/3511861.3511863
- ↑ Husein, Rasha Ahmad; Aburajouh, Hala; Catal, Cagatay (março de 2025). «Large language models for code completion: A systematic literature review». Computer Standards & Interfaces. 92 (103917). doi:10.1016/j.csi.2024.103917
- ↑ Weissenow, Konstantin; Rost, Burkhard (abril de 2025). «Are protein language models the new universal key?». Current Opinion in Structural Biology. 91 (102997). PMID 39921962. doi:10.1016/j.sbi.2025.102997
- ↑ Lin, Zeming; Akin, Halil; Rao, Roshan; Hie, Brian; Zhu, Zhongkai; Lu, Wenting; Smetanin, Nikita; Verkuil, Robert; Kabeli, Ori; Shmueli, Yaniv; dos Santos Costa, Allan; Fazel-Zarandi, Maryam; Sercu, Tom; Candido, Salvatore; Rives, Alexander (17 de março de 2023). «Evolutionary-scale prediction of atomic-level protein structure with a language model». Science. 379 (6637): 1123–1130. Bibcode:2023Sci...379.1123L. PMID 36927031. bioRxiv 10.1101/2022.07.20.500902 Verifique
|biorxiv=value (ajuda). doi:10.1126/science.ade2574 - ↑ «ESM Metagenomic Atlas | Meta AI». esmatlas.com (em inglês)
- ↑ Hayes, Thomas; Rao, Roshan; Akin, Halil; Sofroniew, Nicholas J.; Oktay, Deniz; Lin, Zeming; Verkuil, Robert; Tran, Vincent Q.; Deaton, Jonathan; Wiggert, Marius; Badkundri, Rohil; Shafkat, Irhum; Gong, Jun; Derry, Alexander; Molina, Raul S.; Thomas, Neil; Khan, Yousuf A.; Mishra, Chetan; Kim, Carolyn; Bartie, Liam J.; Nemeth, Matthew; Hsu, Patrick D.; Sercu, Tom; Candido, Salvatore; Rives, Alexander (21 de fevereiro de 2025). «Simulating 500 million years of evolution with a language model». Science. 387 (6736): 850–858. Bibcode:2025Sci...387..850H. PMID 39818825. doi:10.1126/science.ads0018
- ↑ Fishman, Veniamin; Kuratov, Yuri; Shmelev, Aleksei; Petrov, Maxim; Penzar, Dmitry; Shepelin, Denis; Chekanov, Nikolay; Kardymon, Olga; Burtsev, Mikhail (11 de janeiro de 2025). «GENA-LM: a family of open-source foundational DNA language models for long sequences». Nucleic Acids Research. 53 (gkae1310). PMC 11734698. PMID 39817513. doi:10.1093/nar/gkae1310
- ↑ Wang, Ning; Bian, Jiang; Li, Yuchen; Li, Xuhong; Mumtaz, Shahid; Kong, Linghe; Xiong, Haoyi (13 de maio de 2024). «Multi-purpose RNA language modelling with motif-aware pretraining and type-guided fine-tuning». Nature Machine Intelligence. 6 (5): 548–557. doi:10.1038/s42256-024-00836-4
- ↑ Hoffmann, Jordan; Borgeaud, Sebastian; Mensch, Arthur; Buchatskaya, Elena; Cai, Trevor; Rutherford, Eliza; Casas, Diego de Las; Hendricks, Lisa Anne; Welbl, Johannes; Clark, Aidan; Hennigan, Tom; Noland, Eric; Millican, Katie; Driessche, George van den; Damoc, Bogdan (29 de março de 2022). «Training Compute-Optimal Large Language Models». NeurIPS: 30016–30030. ISBN 978-1-7138-7108-8
- 1 2 Caballero, Ethan; Gupta, Kshitij; Rish, Irina; Krueger, David (2022). «Broken Neural Scaling Laws». arXiv:2210.14891
- 1 2 Wei, Jason; Tay, Yi; Bommasani, Rishi; Raffel, Colin; Zoph, Barret; Borgeaud, Sebastian; Yogatama, Dani; Bosma, Maarten; Zhou, Denny; Metzler, Donald; Chi, Ed H.; Hashimoto, Tatsunori; Vinyals, Oriol; Liang, Percy; Dean, Jeff; Fedus, William (31 de agosto de 2022). «Emergent Abilities of Large Language Models». Transactions on Machine Learning Research. ISSN 2835-8856. Consultado em 19 de março de 2023. Cópia arquivada em 22 de março de 2023
- ↑ «137 emergent abilities of large language models». Jason Wei. Consultado em 24 de junho de 2023
- ↑ Bowman, Samuel R. (2024). «Eight Things to Know about Large Language Models». Critical AI. 2 (2). doi:10.1215/2834703X-11556011
- ↑ Hahn, Michael; Goyal, Navin (2024). «A survey on large language model based autonomous agents». Frontiers of Computer Science. 18 (186345). arXiv:2303.07971. doi:10.1007/s11704-024-40231-1
- ↑ Pilehvar, Mohammad Taher; Camacho-Collados, Jose (junho de 2019). «Proceedings of the 2019 Conference of the North». Minneapolis, Minnesota: Association for Computational Linguistics. Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers): 1267–1273. doi:10.18653/v1/N19-1128. Consultado em 27 de junho de 2023. Cópia arquivada em 27 de junho de 2023
- ↑ «WiC: The Word-in-Context Dataset». pilehvar.github.io. Consultado em 27 de junho de 2023. Cópia arquivada em 27 de junho de 2023
- ↑ Patel, Roma; Pavlick, Ellie (6 de outubro de 2021). «Mapping Language Models to Grounded Conceptual Spaces». ICLR. Consultado em 27 de junho de 2023. Cópia arquivada em 24 de junho de 2023
- ↑ A Closer Look at Large Language Models Emergent Abilities Arquivado em 2023-06-24 no Wayback Machine (Yao Fu, 20 de novembro de 2022)
- ↑ Ornes, Stephen (16 de março de 2023). «The Unpredictable Abilities Emerging From Large AI Models». Quanta Magazine. Consultado em 16 de março de 2023. Cópia arquivada em 16 de março de 2023
- ↑ Schaeffer, Rylan; Miranda, Brando; Koyejo, Sanmi (1 de abril de 2023). «Are Emergent Abilities of Large Language Models a Mirage?». NeurIPS. arXiv:2304.15004
- ↑ Nanda, Neel; Chan, Lawrence; Lieberum, Tom; Smith, Jess; Steinhardt, Jacob (1 de janeiro de 2023). «Progress measures for grokking via mechanistic interpretability». arXiv:2301.05217
- ↑ Ananthaswamy, Anil (12 de abril de 2024). «How Do Machines 'Grok' Data?». Quanta Magazine (em inglês). Consultado em 30 de junho de 2025
- 1 2 3 4 5 Mitchell, Melanie; Krakauer, David C. (28 de março de 2023). «The debate over understanding in AI's large language models». Proceedings of the National Academy of Sciences. 120 (e2215907120). Bibcode:2023PNAS..12015907M. PMC 10068812. PMID 36943882. arXiv:2210.13966. doi:10.1073/pnas.2215907120
- ↑ Metz, Cade (16 de maio de 2023). «Microsoft Says New A.I. Shows Signs of Human Reasoning». The New York Times
- 1 2 Bubeck, Sébastien; Chandrasekaran, Varun; Eldan, Ronen; Gehrke, Johannes; Horvitz, Eric; Kamar, Ece; Lee, Peter; Lee, Yin Tat; Li, Yuanzhi; Lundberg, Scott; Nori, Harsha; Palangi, Hamid; Ribeiro, Marco Tulio; Zhang, Yi (2023). «Machine culture». Nature Human Behaviour. 7 (11): 1855–1868. PMID 37985914. arXiv:2303.12712. doi:10.1038/s41562-023-01742-2
- ↑ «Anthropic CEO Dario Amodei pens a smart look at our AI future». Fast Company. 17 de outubro de 2024
- ↑ «ChatGPT is more like an 'alien intelligence' than a human brain, says futurist». ZDNET. 2023. Consultado em 12 de junho de 2023. Cópia arquivada em 12 de junho de 2023
- 1 2 Newport, Cal (13 de abril de 2023). «What Kind of Mind Does ChatGPT Have?». The New Yorker. Consultado em 12 de junho de 2023. Cópia arquivada em 12 de junho de 2023
- ↑ Roose, Kevin (30 de maio de 2023). «Why an Octopus-like Creature Has Come to Symbolize the State of A.I.». The New York Times. Consultado em 12 de junho de 2023. Cópia arquivada em 30 de maio de 2023
- ↑ «The A to Z of Artificial Intelligence». Time Magazine. 13 de abril de 2023. Consultado em 12 de junho de 2023. Cópia arquivada em 16 de junho de 2023
- ↑ Sekrst, Kristina (2025). The Illusion Engine: The Quest for Machine Consciousness. [S.l.]: Springer. ISBN 978-3-032-05561-3
- ↑ Ji, Ziwei; Lee, Nayeon; Frieske, Rita; Yu, Tiezheng; Su, Dan; Xu, Yan; Ishii, Etsuko; Bang, Yejin; Dai, Wenliang; Madotto, Andrea; Fung, Pascale (novembro de 2022). «Survey of Hallucination in Natural Language Generation» (pdf). Association for Computing Machinery. ACM Computing Surveys. 55 (12): 1–38. arXiv:2202.03629. doi:10.1145/3571730. Consultado em 15 de janeiro de 2023. Cópia arquivada em 26 de março de 2023
- ↑ Varshney, Neeraj; Yao, Wenlin; Zhang, Hongming; Chen, Jianshu; Yu, Dong (2023). «A Stitch in Time Saves Nine: Detecting and Mitigating Hallucinations of LLMs by Validating Low-Confidence Generation». arXiv:2307.03987
- ↑ Lin, Belle (5 de fevereiro de 2025). «Why Amazon is Betting on 'Automated Reasoning' to Reduce AI's Hallucinations: The tech giant says an obscure field that combines AI and math can mitigate—but not completely eliminate—AI's propensity to provide wrong answers». Wall Street Journal. ISSN 0099-9660
- ↑ Lakoff, George (1999). Philosophy in the Flesh: The Embodied Mind and Its Challenge to Western Philosophy; Appendix: The Neural Theory of Language Paradigm. [S.l.]: New York Basic Books. pp. 569–583. ISBN 978-0-465-05674-3
- ↑ Evans, Vyvyan. (2014). The Language Myth. [S.l.]: Cambridge University Press. ISBN 978-1-107-04396-1
- ↑ Friston, Karl J. (2022). Active Inference: The Free Energy Principle in Mind, Brain, and Behavior; Chapter 4 The Generative Models of Active Inference. [S.l.]: The MIT Press. ISBN 978-0-262-36997-8
- ↑ Brown, Tom B.; Mann, Benjamin; Ryder, Nick; Subbiah, Melanie; Kaplan, Jared; Dhariwal, Prafulla; Neelakantan, Arvind; Shyam, Pranav; Sastry, Girish; Askell, Amanda; Agarwal, Sandhini; Herbert-Voss, Ariel; Krueger, Gretchen; Henighan, Tom; Child, Rewon; Ramesh, Aditya; Ziegler, Daniel M.; Wu, Jeffrey; Winter, Clemens; Hesse, Christopher; Chen, Mark; Sigler, Eric; Litwin, Mateusz; Gray, Scott; Chess, Benjamin; Clark, Jack; Berner, Christopher; McCandlish, Sam; Radford, Alec; Sutskever, Ilya; Amodei, Dario (dezembro de 2020). «Language Models are Few-Shot Learners» (PDF). Curran Associates, Inc. Advances in Neural Information Processing Systems. 33: 1877–1901. Consultado em 14 de março de 2023. Cópia arquivada (PDF) em 17 de novembro de 2023
- 1 2 Huyen, Chip (18 de outubro de 2019). «Evaluation Metrics for Language Modeling». The Gradient. Consultado em 14 de janeiro de 2024
- ↑ Shannon, Claude E. (1948). «A Mathematical Theory of Communication». Bell System Technical Journal. 27 (3): 379–423. Bibcode:1948BSTJ...27..379S. doi:10.1002/j.1538-7305.1948.tb01338.x
- ↑ Edwards, Benj (28 de setembro de 2023). «AI language models can exceed PNG and FLAC in lossless compression, says study». Ars Technica (em inglês). Consultado em 29 de maio de 2025
- ↑ «openai/simple-evals». OpenAI. 28 de maio de 2024. Consultado em 28 de maio de 2024
- ↑ «openai/evals». OpenAI. 28 de maio de 2024. Consultado em 28 de maio de 2024. Cópia arquivada em 8 de maio de 2024
- 1 2 Clark, Christopher; Lee, Kenton; Chang, Ming-Wei; Kwiatkowski, Tom; Collins, Michael; Toutanova, Kristina (2019). «BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions». ACL: 2924–2936. doi:10.18653/v1/N19-1300
- 1 2 3 Zhao, Wayne Xin; Zhou, Kun; Li, Junyi; Tang, Tianyi; Wang, Xiaolei; Hou, Yupeng; Min, Yingqian; Zhang, Beichen; Zhang, Junjie; Dong, Zican; Du, Yifan; Yang, Chen; Chen, Yushuo; Chen, Zhipeng; Jiang, Jinhao; Ren, Ruiyang; Li, Yifan; Tang, Xinyu; Liu, Zikang; Liu, Peiyu; Nie, Jian-Yun; Wen, Ji-Rong (2023). «A Survey of Large Language Models». arXiv:2303.18223
- ↑ Nangia, Nikita; Vania, Clara; Bhalerao, Rasika; Bowman, Samuel R. (novembro de 2020). CrowS-Pairs: A Challenge Dataset for Measuring Social Biases in Masked Language Models. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics. pp. 1953–1967. arXiv:2010.00133. doi:10.18653/v1/2020.emnlp-main.154
- ↑ Nadeem, Moin; Bethke, Anna; Reddy, Siva (agosto de 2021). StereoSet: Measuring stereotypical bias in pretrained language models. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). Association for Computational Linguistics. pp. 5356–5371. arXiv:2004.09456. doi:10.18653/v1/2021.acl-long.416
- ↑ Simpson, Shmona; Nukpezah, Jonathan; Kie Brooks; Pandya, Raaghav (17 de dezembro de 2024). «Parity benchmark for measuring bias in LLMs». Springer. AI and Ethics. 5 (3): 3087–3101. doi:10.1007/s43681-024-00613-4
- ↑ Caramancion, Kevin Matthe (13 de novembro de 2023). «News Verifiers Showdown: A Comparative Performance Evaluation of ChatGPT 3.5, ChatGPT 4.0, Bing AI, and Bard in News Fact-Checking». 2023 IEEE Future Networks World Forum (FNWF). [S.l.]: IEEE. pp. 1–6. ISBN 979-8-3503-2458-7. arXiv:2306.17176. doi:10.1109/FNWF58287.2023.10520446
- ↑ Bermejo, Vicente J.; Gago, Andrés; Gálvez, Ramiro H.; Harari, Nicolás (2025). «LLMs outperform outsourced human coders on complex textual analysis». Nature Portfolio. Scientific Reports. 15 (1). Bibcode:2025NatSR..1540122B. PMC 12623721. PMID 41249236 Verifique
|pmid=(ajuda). doi:10.1038/s41598-025-23798-y - ↑ Gilardi, Fabrizio; Alizadeh, Meysam; Kubli, Maël (2023). «ChatGPT outperforms crowd workers for text-annotation tasks». National Academy of Sciences. Proceedings of the National Academy of Sciences of the United States of America. 120 (e2305016120). Bibcode:2023PNAS..12005016G. PMC 10372638. PMID 37463210. arXiv:2303.15056. doi:10.1073/pnas.2305016120
- ↑ «Sanitized open-source datasets for natural language and code understanding: how we evaluated our 70B model». imbue.com (em inglês). Consultado em 24 de julho de 2024. Cópia arquivada em 26 de julho de 2024
- ↑ Srivastava, Aarohi; Rastogi, Abhinav; Rao, Abhishek; Abu Awal Md Shoeb; Abid, Abubakar; Fisch, Adam; Brown, Adam R.; Santoro, Adam; Gupta, Aditya; Garriga-Alonso, Adrià; Kluska, Agnieszka; Lewkowycz, Aitor; Agarwal, Akshat; Power, Alethea; Ray, Alex; Warstadt, Alex; Kocurek, Alexander W.; Safaya, Ali; Tazarv, Ali; Xiang, Alice; Parrish, Alicia; Nie, Allen; Hussain, Aman; Askell, Amanda; Dsouza, Amanda; Slone, Ambrose; Rahane, Ameet; Iyer, Anantharaman S.; Andreassen, Anders; Madotto, Andrea (2022). «Beyond the Imitation Game: Quantifying and extrapolating the capabilities of language models». TMLR. arXiv:2206.04615
- ↑ Niven, Timothy; Kao, Hung-Yu (2019). «Probing Neural Network Comprehension of Natural Language Arguments». ACL: 4658–4664. doi:10.18653/v1/P19-1459
- ↑ Lin, Stephanie; Hilton, Jacob; Evans, Owain (2021). «TruthfulQA: Measuring How Models Mimic Human Falsehoods». ACL. arXiv:2109.07958
- 1 2 Zellers, Rowan; Holtzman, Ari; Bisk, Yonatan; Farhadi, Ali; Choi, Yejin (2019). «HellaSwag: Can a Machine Really Finish Your Sentence?». ACL. arXiv:1905.07830
- ↑ «Extracting Training Data from Large Language Models» (PDF). USENIX Security. 2021
- 1 2 Xu, Weijie; Wang, Yiwen; Xue, Chi; Hu, Xiangkun; Fang, Xi; Dong, Guimin; Reddy, Chandan K. (28 de junho de 2025). «Quantifying Fairness in LLMs Beyond Tokens: A Semantic and Statistical Perspective». COLM. arXiv:2506.19028
- ↑ «Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings» (PDF). NeurIPS. 2016
- 1 2 Bender, Emily M.; Gebru, Timnit; McMillan-Major, Margaret (3 de março de 2021). «On the Dangers of Stochastic Parrots: Can Language Models Be Too Big?» (PDF). FAccT. Consultado em 2 de outubro de 2025
- ↑ Luo, Queenie; Puett, Michael J.; Smith, Michael D. (22 de julho de 2024). «A Perspectival Mirror of the Elephant». Communications of the ACM (em inglês). 67 (8): 98–105. doi:10.1145/3670241
- ↑ Hofmann, Valentin; Kalluri, Pratyusha Ria; Jurafsky, Dan; King, Sharese (5 de setembro de 2024). «AI generates covertly racist decisions about people based on their dialect». Nature (em inglês). 633 (8028): 147–154. Bibcode:2024Natur.633..147H. ISSN 0028-0836. PMC 11374696. PMID 39198640. doi:10.1038/s41586-024-07856-5
- ↑ Wang, Angelina; Morgenstern, Jamie; Dickerson, John P. (17 de fevereiro de 2025). «Large language models that replace human participants can harmfully misportray and flatten identity groups». Nature Machine Intelligence. 7 (3): 400–411. arXiv:2402.01908. doi:10.1038/s42256-025-00986-z
- ↑ Cheng, Myra; Durmus, Esin; Jurafsky, Dan (29 de maio de 2023). «Marked Personas: Using Natural Language Prompts to Measure Stereotypes in Language Models». arXiv:2305.18189
- ↑ Kotek, Hadas; Dockum, Rikker; Sun, David (5 de novembro de 2023). «Gender bias and stereotypes in Large Language Models». Proceedings of the ACM Collective Intelligence Conference. New York, NY, USA: Association for Computing Machinery. pp. 12–24. ISBN 979-8-4007-0113-9. arXiv:2308.14921. doi:10.1145/3582269.3615599
- ↑ Gao, Bufan; Kreiss, Elisa (10 de setembro de 2025). «Measuring Bias or Measuring the Task: Understanding the Brittle Nature of LLM Gender Biases». arXiv:2509.04373
- ↑ Choi, Hyeong Kyu; Xu, Weijie; Xue, Chi; Eckman, Stephanie; Reddy, Chandan K. (27 de setembro de 2024). «Mitigating Selection Bias with Node Pruning and Auxiliary Options». arXiv:2409.18857
- ↑ Zheng, Chujie; Zhou, Hao; Meng, Fandong; Zhou, Jie; Huang, Minlie (7 de setembro de 2023). «Large Language Models Are Not Robust Multiple Choice Selectors». arXiv:2309.03882
- ↑ Heikkilä, Melissa (7 de agosto de 2023). «AI language models are rife with different political biases». MIT Technology Review. Consultado em 29 de dezembro de 2023
- ↑ Amodei, Dario; Olah, Chris; Steinhardt, Jacob; Christiano, Paul; Schulman, John; Mané, Dan (21 de junho de 2016). «Concrete Problems in AI Safety». arXiv:1606.06565
- ↑ Lyons, Jessica (26 de setembro de 2025). «Prompt injection – and a $5 domain – trick Salesforce Agentforce into leaking sales». The Register. Consultado em 26 de setembro de 2025
- ↑ Carlini, Nicholas; Tramèr, Florian; Wallace, Eric (11 de agosto de 2021). «Extracting Training Data from Large Language Models» (PDF). USENIX Association. Consultado em 2 de outubro de 2025
- ↑ Zhao, Yao; Zhang, Yun; Sun, Yong (7 de junho de 2023). «The debate over understanding in AI's large language models». Proceedings of the National Academy of Sciences. 120 (e2215907120). Bibcode:2023PNAS..12015907M. PMC 10068812. PMID 36943882. arXiv:2306.05499. doi:10.1073/pnas.2215907120
- ↑ Buolamwini, Joy; Gebru, Timnit (1 de janeiro de 2018). «Gender Shades: Intersectional Accuracy Disparities in Commercial Gender Classification» (PDF). Proceedings of Machine Learning Research (FAT*). Consultado em 2 de outubro de 2025
- ↑ Yang, Kaiqi (1 de novembro de 2024). «Unpacking Political Bias in Large Language Models: A Cross-Model Comparison on U.S. Politics». arXiv:2412.16746
- ↑ Strubell, Emma; Ganesh, Ananya; McCallum, Andrew (28 de julho de 2019). «Energy and Policy Considerations for Deep Learning in NLP» (PDF). ACL Anthology. Consultado em 2 de outubro de 2025
- ↑ He, Yuhao; Yang, Li; Qian, Chunlian; Li, Tong; Su, Zhengyuan; Zhang, Qiang; Hou, Xiangqing (28 de abril de 2023). «Conversational Agent Interventions for Mental Health Problems: Systematic Review and Meta-analysis of Randomized Controlled Trials». Journal of Medical Internet Research. 25 (e43862). PMC 10182468. PMID 37115595. doi:10.2196/43862
- ↑ Pauketat, Janet V.T.; Ladak, Ali; Anthis, Jacy Reese (2025). «World-Making for a Future with Sentient AI» (PDF). The British Journal of Social Psychology. 64 (e12844). PMID 39737875. doi:10.1111/bjso.12844. Consultado em 2 de outubro de 2025
- ↑ Anthis, Jacy Reese; Pauketat, Janet V.T. (2025). «Perceptions of Sentient AI and Other Digital Minds: Evidence from the AI, Morality, and Sentience (AIMS) Survey». Proceedings of the 2025 CHI Conference on Human Factors in Computing Systems. [S.l.: s.n.] pp. 1–22. ISBN 979-8-4007-1394-1. arXiv:2407.08867. doi:10.1145/3706598.3713329
- ↑ Amodei, Dario; Olah, Chris; Steinhardt, Jacob (17 de junho de 2016). «Concrete Problems in AI Safety». arXiv:1606.06565
- ↑ Alba, Davey (1 de maio de 2023). «AI chatbots have been used to create dozens of news content farms». The Japan Times. Consultado em 18 de junho de 2023
- ↑ «Could chatbots help devise the next pandemic virus?». Science. 14 de junho de 2023. doi:10.1126/science.adj2463. Consultado em 18 de junho de 2023. Cópia arquivada em 18 de junho de 2023
- ↑ Kang, Daniel (2023). «Exploiting programmatic behavior of LLMs: Dual-use through standard security attacks». IEEE Security and Privacy Workshops. arXiv:2302.05733
- 1 2 «Russian propaganda may be flooding AI models». The American Sunlight Project (em inglês). 26 de fevereiro de 2025. Consultado em 11 de abril de 2025
- ↑ Goudarzi, Sara (26 de março de 2025). «Russian networks flood the Internet with propaganda, aiming to corrupt AI chatbots». Bulletin of the Atomic Scientists (em inglês). Consultado em 10 de abril de 2025
- ↑ Wang, Yongge (20 de junho de 2024). «Encryption Based Covert Channel for Large Language Models» (PDF). IACR ePrint 2024/586. Consultado em 24 de junho de 2024. Cópia arquivada (PDF) em 24 de junho de 2024
- ↑ Sharma, Mrinank; Tong, Meg; Korbak, Tomasz (20 de outubro de 2023). «Towards Understanding Sycophancy in Language Models». arXiv:2310.13548
- ↑ Rrv, Aswin; Tyagi, Nemika (11 de agosto de 2024). «Chaos with Keywords: Exposing Large Language Models Sycophancy to Misleading Keywords and Evaluating Defense Strategies» (PDF). ACL Anthology. Consultado em 2 de outubro de 2025
- ↑ Salvi, Francesco; Horta Ribeiro, Manoel; Gallotti, Riccardo (19 de maio de 2025). «On the conversational persuasiveness of GPT-4». Nature Human Behaviour. 9 (8): 1645–1653. PMC 12367540. PMID 40389594. doi:10.1038/s41562-025-02194-6
- ↑ Østergaard, Søren Dinesen (25 de agosto de 2023). «Will Generative Artificial Intelligence Chatbots Generate Delusions in Individuals Prone to Psychosis?». Schizophrenia Bulletin. 49 (6): 1418–1419. PMC 10686326. PMID 37625027. doi:10.1093/schbul/sbad128
- ↑ Rosenberg, Josh (21 de agosto de 2025). «South Park Calls Out ChatGPT and Useless Tech-Bro Sycophants». Esquire. Consultado em 2 de outubro de 2025
- ↑ «openai-python/chatml.md at v0.27.6 · openai/openai-python». GitHub (em inglês)
- ↑ Douglas, Will (3 de março de 2023). «The inside story of how ChatGPT was built from the people who made it». MIT Technology Review. Consultado em 6 de março de 2023. Cópia arquivada em 3 de março de 2023
- ↑ Greshake, Kai; Abdelnabi, Sahar; Mishra, Shailesh; Endres, Christoph; Holz, Thorsten; Fritz, Mario (2023). «Not What You've Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection». Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security. [S.l.: s.n.] pp. 79–90. ISBN 979-8-4007-0260-0. doi:10.1145/3605764.3623985
- ↑ Edwards, Benj (15 de janeiro de 2024). «AI poisoning could turn models into destructive "sleeper agents," says Anthropic». Ars Technica (em inglês). Consultado em 19 de julho de 2025
- ↑ «U.S. judge approves $1.5 billion Anthropic copyright settlement with authors». Reuters. 25 de setembro de 2025. Consultado em 26 de setembro de 2025
- ↑ «Anthropic reaches $1.5B settlement with authors over AI copyright claims». Associated Press. 25 de setembro de 2025. Consultado em 26 de setembro de 2025
- ↑ «Meta fends off authors' U.S. copyright lawsuit over AI». Reuters. 25 de junho de 2025. Consultado em 26 de junho de 2025
- ↑ «Meta Scores Victory in AI Copyright Case». Wired. 25 de junho de 2025. Consultado em 26 de junho de 2025
- ↑ «OpenAI defeats news outlets' copyright lawsuit over AI training for now». Reuters. 7 de novembro de 2024. Consultado em 8 de novembro de 2024
- ↑ Robison, Kylie (21 de novembro de 2024). «OpenAI erases evidence in training data lawsuit». The Verge. Consultado em 22 de novembro de 2024
- ↑ Peng, Zhencan; Wang, Zhizhi; Deng, Dong (13 de junho de 2023). «Near-Duplicate Sequence Search at Scale for Large Language Model Memorization Evaluation» (PDF). Proceedings of the ACM on Management of Data. 1 (2): 1–18. doi:10.1145/3589324. Consultado em 20 de janeiro de 2024. Cópia arquivada (PDF) em 27 de agosto de 2024 Citando Lee et al 2022.
- ↑ Peng, Wang & Deng 2023, p. 8.
- ↑ Council, Stephen (1 de dezembro de 2023). «How Googlers cracked an SF rival's tech model with a single word». SFGate. Cópia arquivada em 16 de dezembro de 2023
- ↑ «Prepare for truly useful large language models». Nature Biomedical Engineering. 7 (2): 85–86. 7 de março de 2023. PMID 36882584. doi:10.1038/s41551-023-01012-6
- ↑ Brinkmann, Levin; Baumann, Fabian; Bonnefon, Jean-François; Derex, Maxime; Müller, Thomas F.; Nussberger, Anne-Marie; Czaplicka, Agnieszka; Acerbi, Alberto; Griffiths, Thomas L.; Henrich, Joseph; Leibo, Joel Z.; McElreath, Richard; Oudeyer, Pierre-Yves; Stray, Jonathan; Rahwan, Iyad (20 de novembro de 2023). «Machine culture». Nature Human Behaviour (em inglês). 7 (11): 1855–1868. ISSN 2397-3374. PMID 37985914. arXiv:2311.11388. doi:10.1038/s41562-023-01742-2
- ↑ Niederhoffer, Kate; Kellerman, Gabriella Rosen; Lee, Angela; Liebscher, Alex; Rapuano, Kristina; Hancock, Jeffrey T. (25 de setembro de 2025). «AI-Generated "Workslop" Is Destroying Productivity». Harvard Business Review (em inglês). Consultado em 22 de setembro de 2025
- ↑ Acar, Oguz A.; Gai, Phyliss Jia; Tu, Yanping; Hou, Jiayi (1 de agosto de 2025). «Research: The Hidden Penalty of Using AI at Work». Harvard Business Review (em inglês). Consultado em 22 de setembro de 2025
- ↑ You, Josh (7 de fevereiro de 2025). «How much energy does ChatGPT use?». Epoch AI. Consultado em 11 de novembro de 2025
- ↑ «Power Hungry: How AI Will Drive Energy Demand». IMF (em inglês). Consultado em 8 de outubro de 2025
- ↑ Mehta, Sourabh (3 de julho de 2024). «How Much Energy Do LLMs Consume? Unveiling the Power Behind AI». Association of Data Scientists (em inglês). Consultado em 27 de janeiro de 2025
- ↑ Luccioni, Sasha; Jernite, Yacine; Strubell, Emma (2024). «Power Hungry Processing: Watts Driving the Cost of AI Deployment?». The 2024 ACM Conference on Fairness Accountability and Transparency. [S.l.: s.n.] pp. 85–99. ISBN 979-8-4007-0450-5. arXiv:2311.16863. doi:10.1145/3630106.3658542
- 1 2 Edwards, Benj (26 de março de 2025). «Open source devs say AI crawlers dominate traffic, forcing blocks on entire countries». Ars Technica. Consultado em 31 de dezembro de 2025
- ↑ Claburn, Thomas (18 de março de 2025). «AI crawlers haven't learned to play nice with websites». The Register. Consultado em 31 de dezembro de 2025
- ↑ Belanger, Ashley (29 de janeiro de 2025). «AI haters build tarpits to trap and trick AI scrapers that ignore robots.txt». Ars Technica. Consultado em 31 de dezembro de 2025
- ↑ Zao-Sanders, Marc (19 de março de 2024). «How People Are Really Using GenAI». Harvard Business Review (em inglês). ISSN 0017-8012. Consultado em 10 de agosto de 2025
- ↑ Rousmaniere, Tony; Zhang, Yimeng; Li, Xu; Shah, Siddharth (21 de julho de 2025). «Large language models as mental health resources: Patterns of use in the United States.». Practice Innovations (em inglês). ISSN 2377-8903. doi:10.1037/pri0000292
- ↑ Ji, Shaoxiong; Zhang, Tianlin; Yang, Kailai; Ananiadou, Sophia; Cambria, Erik (17 de dezembro de 2023). «Rethinking Large Language Models in Mental Health Applications». arXiv:2311.11267
- ↑ Moore, Jared; Grabb, Declan; Agnew, William; Klyman, Kevin; Chancellor, Stevie; Ong, Desmond C.; Haber, Nick (25 de abril de 2025). «Expressing stigma and inappropriate responses prevents LLMS from safely replacing mental health providers». Proceedings of the 2025 ACM Conference on Fairness, Accountability, and Transparency. [S.l.: s.n.] pp. 599–627. ISBN 979-8-4007-1482-5. arXiv:2504.18412. doi:10.1145/3715275.3732039
- ↑ Grabb, Declan; Lamparth, Max; Vasan, Nina (14 de agosto de 2024). «Risks from Language Models for Automated Mental Healthcare: Ethics and Structure for Implementation». arXiv:2406.11852
- ↑ McBain, Ryan K.; Cantor, Jonathan H.; Zhang, Li Ang; Baker, Olesya; Zhang, Fang; Halbisen, Alyssa; Kofner, Aaron; Breslau, Joshua; Stein, Bradley; Mehrotra, Ateev; Yu, Hao (5 de março de 2025). «Competency of Large Language Models in Evaluating Appropriate Responses to Suicidal Ideation: Comparative Study». Journal of Medical Internet Research (em inglês). 27 (e67891). PMC 11928068. PMID 40053817. doi:10.2196/67891
- ↑ Li, Fei-Fei; Etchemendy, John (22 de maio de 2024). «No, Today's AI Isn't Sentient. Here's How We Know». Time. Consultado em 22 de maio de 2024
- ↑ Chalmers, David J. (9 de agosto de 2023). «Could a Large Language Model Be Conscious?». Boston Review
- ↑ Thomson, Jonny (31 de outubro de 2022). «Why don't robots have rights?». Big Think. Consultado em 23 de fevereiro de 2024. Cópia arquivada em 13 de setembro de 2024
- ↑ Kateman, Brian (24 de julho de 2023). «AI Should Be Terrified of Humans». Time. Consultado em 23 de fevereiro de 2024. Cópia arquivada em 25 de setembro de 2024
- ↑ Metzinger, Thomas (2021). «Artificial Suffering: An Argument for a Global Moratorium on Synthetic Phenomenology». Journal of Artificial Intelligence and Consciousness. 08: 43–66. doi:10.1142/S270507852150003X
- ↑ Tkachenko, Yegor (2024). «Position: Enforced Amnesia as a Way to Mitigate the Potential Risk of Silent Suffering in the Conscious AI». ICML. 235: 48362–48368
- ↑ Leith, Sam (9 de julho de 2022). «Nick Bostrom: How can we be certain a machine isn't conscious?». The Spectator. Consultado em 22 de setembro de 2025
- ↑ Chalmers, David (1995). «Facing up to the problem of consciousness». Journal of Consciousness Studies. 2 (3): 200–219. CiteSeerX 10.1.1.103.8362
- ↑ Maruf, Ramishah (25 de julho de 2022). «Google fires engineer who contended its AI technology was sentient». CNN. Consultado em 22 de setembro de 2025
Leitura complementar
- Jurafsky, Dan; Martin, James H. (2023). Speech and Language Processing: An Introduction to Natural Language Processing, Computational Linguistics, and Speech Recognition (PDF) 3 ed. [S.l.: s.n.]
- Yin, Shukang; Fu, Chaoyou; Zhao, Sirui; Li, Ke; Sun, Xing; Xu, Tong; Chen, Enhong (2024). «A Survey on Multimodal Large Language Models». National Science Review. 11 (12): nwae403. PMC 11645129. PMID 39679213. arXiv:2306.13549. doi:10.1093/nsr/nwae403
- «AI Index Report 2024 – Artificial Intelligence Index». Stanford AI Index. Consultado em 5 de maio de 2024
- Frank, Michael C. (27 de junho de 2023). «Baby steps in evaluating the capacities of large language models». Nature Reviews Psychology. 2 (8): 451–452. ISSN 2731-0574. doi:10.1038/s44159-023-00211-x. Consultado em 2 de julho de 2023
- Raschka, Sebastian (11 de março de 2026). «The Big LLM Architecture Comparison: From DeepSeek V3 to GLM-5: A Look At Modern LLM Architecture Design». Sebastian Raschka’s AI Magazine. Consultado em 25 de março de 2026
| Estados Unidos |
|
|---|---|
| China |
|
| Extintos |
|
| Relacionados | |
| |