Complementaridade (biologia molecular)
Em biologia molecular complementaridade é a propriedade partilhada por duas sequências de ácidos nucleicos que, quando ambas estão alinhadas de forma antiparalela, as bases nitrogenadas dos nucleotídeos de uma das sequências em cada posição correspondem na outra sequência a outra base específica, sempre a mesma, que é considerada sua complementar. Portanto, a complementaridade é uma complementaridade de bases. Formam-se duas bases pares de bases de Watson e Crick, que podem estabelecer ligações de hidrogénio estáveis entre elas. O grau de complementaridade entre duas cadeias de ácidos nucleicos comparadas varia muito, de completa a nenhuma, e mesmo os ácidos nucleicos de espécies diferentes podem apresentar um grau de complementaridade que lhes permite hibridizar em certos tramos. As duas cadeias de ADN são complementares entre si, e um ARN finalizado da transcrição é complementar da parte da cadeia antisentido ou molde do ADN a partir do qual foi transcrito.
Regras de complementaridade
.png)

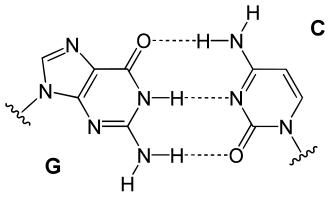
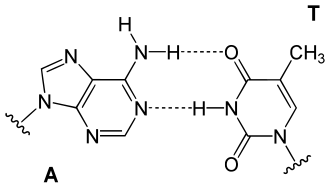
No ADN, a base adenina (A) é complementar da timina (T) e vice-versa; a guanina (G) é complementar da citosina (C) e vice-versa.
A maioria dos RNAs são de cadeia simples, mas podem apresentar trechos complementares que se encontram e se unem quando a molécula se dobra, o que lhes confere uma estrutura tridimensional; neste caso, a complementaridade é da adenina com a uracila (o RNA possui uracila em vez de timina) e da guanina com a citosina. O mesmo acontece nos ARN de cadeia dupla de certos vírus.
Durante a transcrição, o RNA é copiado do ADN. Neste caso, as correspondências são timina (no ADN) com adenina (no ARN), adenina (no ADN) com uracilo (no ARN) e guanina com citosina e vice-versa. Na transcrição inversa, o ADN é copiado de um molde de ARN e as correspondências são adenina (no ARN) com timina (no ADN), uracilo (no ARN) com adenina (no ADN) e guanina com citosina e vice-versa.
Como existe apenas uma base complementar possível para cada uma das bases que se encontram no ADN ou no ARN, pode ser reconstruída uma cadeia complementar para qualquer cadeia de ácido nucleico cuja sequência seja conhecida. Na replicação do ADN e na transcrição, uma das cadeias é utilizada como molde para sintetizar a cadeia complementar.[1]
Por exemplo, dada a seguinte cadeia de ADN
- 5' A G T C A T G 3'
A sua sequência complementar é
- 3' T C A G T A C 5'
Como se pode observar, as duas fitas são antiparalelas, pois uma começa na extremidade 5' e termina na extremidade 3' e a outra vice-versa. No entanto, frequentemente a fita complementar é escrita como o complemento inverso, com a extremidade 5' sempre posicionada à esquerda e a extremidade 3' à direita por convenção, pelo que ficaria assim:
- 5' C A T G A C T 3'
Se um trecho de ácido nucleico tiver uma sequência que seja a mesma Como seu complemento reverso, diz-se que é uma sequência palíndrómica.
Causa
Um número suficiente de ligações de hidrogénio estáveis não pode ser formado com qualquer combinação de bases. Para que tal seja possível, as bases opostas devem ter os grupos químicos da natureza correta e na posição correta para a formação de ligações de hidrogénio. Isto só é possível quando nos deparamos com A e T ou A e U (que formam duas ligações de hidrogénio) ou C e G (que formam três). Ou seja, A=T, G≡C (ou A=U entre ADN e ARN). Uma base purina liga-se sempre a uma base pirimidina. Outras combinações não seriam capazes de formar ligações de hidrogénio corretamente, pelo que são impossíveis ou raras.
Códigos ambíguos
Em biologia sistemática, pode ser necessário suplementar os códigos IUPAC para ácidos nucleicos que significam "qualquer um dos dois" ou "qualquer um dos três". O código R (que representa qualquer purina) pode ser complementado com Y (qualquer pirimidina) e M (grupo amino com K (grupo ceto). W (fraco, referindo-se à força da ligação, do inglês weak) e S (forte, de strong) não são frequentemente trocados atualmente,[2] embora algumas ferramentas as tenham trocado anteriormente.[3] S e W referem-se ao número de ligações de hidrogénio com as quais os nucleótidos estão ligados para formar pares complementares.[1]
O código que exclui especificamente um dos três nucleótidos pode ser complementado com um código que exclui o nucleótido que complementa o que foi excluído anteriormente. Por exemplo, V (que pode ser A, C ou G, mas "não T") pode ser complementado com B (que pode ser C, G ou T, mas "não A"). Como se pode ver, como excluímos anteriormente o T, excluímos o A (porque era ele que complementava o T).
Ambigramas
Ao atribuir os caracteres ambigráficos apropriados às bases complementares (por exemplo, guanina = b, citosina = q, adenina = n e timina = u), é possível obter a sequência complementar de sequências inteiras de ADN simplesmente rodando o texto para a esquerda (reflexo) e depois virando-o "de pernas para o ar".[4] Note-se que, com estas duas operações, a letra b passa a ser q, e vice-versa, e o mesmo com u e n. Por exemplo, buqn (GTCA) seria lido como ubnq (TGAC, complemento inverso).[5]
Referências
- ↑ a b Reverse-complement tool página com o código de conversão IUPAC documentado.
- ↑ Jeremiah Faith (2011), tabela de conversão
- ↑ arep.med.harvard.edu Uma página de ferramentas com uma nota sobre a conversão W-S aplicada.
- ↑ Rozak DA (2006). «The practical and pedagogical advantages of an ambigraphic nucleic acid notation». Nucleosides Nucleotides Nucleic Acids. 25 (7): 807–13. PMID 16898419. doi:10.1080/15257770600726109
- ↑ Flower, R. H.; Knoll, A. H.; Yuan, X. (1955). "Status of Endoceroid Classification". Journal of Paleontology 29 (3): 329–371. doi 10.2144/000112727. [1] Arquivado em 2013-10-04 no Wayback Machine