Algoritmo FFT de Cooley–Tukey
O algoritmo de Cooley-Tukey, nomeado em homenagem a J. W. Cooley e John Tukey, é o algoritmo de transformada rápida de Fourier (FFT) mais comum. Ele reexpressa a transformada discreta de Fourier (DFT) de um tamanho composto arbitrário em termos de N1 DFTs menores de tamanho N2, recursivamente, para reduzir o tempo de computação para O(N log N) quando N é altamente composto. Devido à importância do algoritmo, variantes específicas e estilos de implementação tornaram-se conhecidos por seus próprios nomes, conforme descrito abaixo.

Como o algoritmo de Cooley-Tukey divide a DFT em DFTs menores, ele pode ser combinado arbitrariamente com qualquer outro algoritmo para a DFT. Por exemplo, o algoritmo de Rader ou o de Bluestein pode ser usado para lidar com grandes fatores primos que não podem ser decompostos pelo algoritmo de Cooley-Tukey, ou o algoritmo de fatores primos pode ser explorado para maior eficiência na separação de fatores relativamente primos.
O algoritmo, juntamente com sua aplicação recursiva, foi inventado por Carl Friedrich Gauss. Cooley e Tukey o redescobriram e popularizaram independentemente 160 anos depois.
História
Esse algoritmo, incluindo sua aplicação recursiva, foi inventado por volta de 1805 por Carl Friedrich Gauss, que o usou para interpolar as trajetórias dos asteroides Pallas e Juno, mas seu trabalho não foi amplamente reconhecido (sendo publicado apenas postumamente e em neolatim).[1][2] Gauss não analisou o tempo computacional assintótico, no entanto. Várias formas limitadas também foram redescobertas diversas vezes ao longo do século XIX e início do século XX.[2] FFTs se tornaram populares depois que James Cooley da IBM e John Tukey de Princeton publicaram um artigo em 1965 reinventando[2] o algoritmo e descrevendo como executá-lo convenientemente em um computador.[3]
Tukey supostamente teve a ideia durante uma reunião do Comitê Consultivo Científico do Presidente Kennedy discutindo maneiras de detectar testes de armas nucleares na União Soviética empregando sismômetros localizados fora do país. Esses sensores gerariam séries temporais sismológicas. No entanto, a análise desses dados exigiria algoritmos rápidos para calcular DFTs devido ao número de sensores e à duração das séries temporais. Essa tarefa foi crítica para a ratificação da proposta de proibição de testes nucleares para que quaisquer violações pudessem ser detectadas sem a necessidade de visitar instalações soviéticas.[4][5] Outro participante daquela reunião, Richard Garwin da IBM, reconheceu o potencial do método e colocou Tukey em contato com Cooley. No entanto, Garwin garantiu que Cooley não soubesse o propósito original. Em vez disso, Cooley foi informado de que isso era necessário para determinar as periodicidades das orientações de spin em um cristal 3-D de hélio-3. Cooley e Tukey publicaram posteriormente seu artigo conjunto, e a ampla adoção ocorreu rapidamente devido ao desenvolvimento simultâneo de conversores analógico-digitais capazes de amostrar em taxas de até 300 kHz.
O fato de Gauss ter descrito o mesmo algoritmo (embora sem analisar seu custo assintótico) não foi percebido até vários anos após o artigo de Cooley e Tukey de 1965. Seu artigo citou como inspiração apenas o trabalho de I. J. Good sobre o que agora é chamado de algoritmo FFT de fator primo (PFA);[3] embora o algoritmo de Good tenha sido inicialmente considerado equivalente ao algoritmo de Cooley-Tukey, rapidamente percebeu-se que o PFA é um algoritmo bastante diferente (funcionando apenas para tamanhos que têm fatores relativamente primos e contando com o teorema do resto chinês, ao contrário do suporte a qualquer tamanho composto presente no algoritmo de Cooley–Tukey).
O caso DIT de base 2
Uma FFT de dizimação no tempo (DIT) de base 2 é a forma mais simples e comum do algoritmo de Cooley-Tukey, embora implementações altamente otimizadas de Cooley-Tukey normalmente utilizem outras formas do algoritmo, conforme descrito abaixo. A DIT de base 2 divide uma DFT de tamanho N em duas DFTs intercaladas (daí o nome "base 2") de tamanho N/2 com cada estágio recursivo.
A transformada discreta de Fourier (DFT) é definida pela fórmula:

onde é um número inteiro que varia de 0 a .


A DIT de base 2 primeiro calcula os DFTs das entradas de índices pares e das entradas de índices ímpares e, em seguida, combina esses dois resultados para produzir a DFT de toda a sequência. Essa ideia pode ser aplicada recursivamente para reduzir o tempo de execução total para O(N log N). Essa forma simplificada assume que N é uma potência de dois; como o número de pontos de amostra N geralmente pode ser escolhido livremente pela aplicação (por exemplo, ajustando a taxa de amostragem ou a janela, aplicando preenchimento com zeros, etc.), isso geralmente não é uma restrição importante.


O algoritmo DIT de base 2 (radix-2 DIT algorithm) reorganiza a DFT da função em duas partes: uma soma sobre os índices pares e uma soma sobre os índices ímpares :




Pode-se fatorar um multiplicador comum da segunda soma, conforme mostrado na equação abaixo. Fica então claro que as duas somas correspondem à DFT da parte de índices pares e à DFT da parte de índices ímpares da função . Denote a DFT das entradas de índices pares por e a DFT das entradas de índices ímpares por e obtemos:






Note que as igualdades são válidas para , mas o ponto crucial é que e são calculados desta forma para somente. Graças à periodicidade do exponencial complexo, também é obtido de e :




Nós podemos reescrever e como:


Este resultado, que expressa a DFT de comprimento N recursivamente em termos de duas DFTs de tamanho N/2, é o núcleo da transformada rápida de Fourier da DIT de base 2. O algoritmo ganha velocidade reutilizando os resultados de cálculos intermediários para calcular múltiplas saídas da DFT. Observe que as saídas finais são obtidas por uma combinação +/− de e , que é simplesmente uma DFT de tamanho 2 (às vezes chamada de "borboleta" neste contexto); quando isso é generalizado para radices maiores que as citadas anteriormente, a DFT de tamanho 2 é substituída por uma DFT maior (que pode ser avaliada com uma FFT).

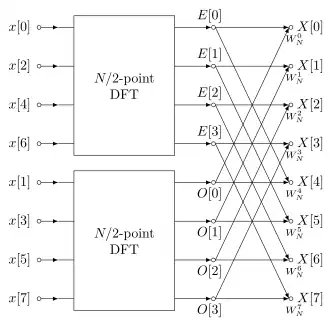
Este processo é um exemplo da técnica geral de algoritmos de dividir para conquistar; em muitas implementações convencionais, no entanto, a recursão explícita é evitada e, em vez disso, percorre-se a árvore computacional em largura.
A reescrita acima de uma DFT de tamanho N como duas DFTs de tamanho N/2 é às vezes chamada de lema de Danielson-Lanczos, uma vez que a identidade foi observada por esses dois autores em 1942 (influenciados pelo trabalho de Runge de 1903). Eles aplicaram seu lema de forma recursiva "reversa", dobrando repetidamente o tamanho da DFT até que o espectro de transformação convergisse (embora eles aparentemente não percebessem a linearidade da complexidade assintótica que eles haviam alcançado, ou seja, de ordem N log N). O trabalho de Danielson–Lanczos antecedeu a ampla disponibilidade de computadores mecânicos ou eletrônicos e exigiu cálculo manual (possivelmente com auxílios mecânicos como máquinas de somar); eles relataram um tempo de computação de 140 minutos para uma DFT de tamanho 64 operando em entradas reais com 3 a 5 dígitos significativos. O artigo de Cooley e Tukey de 1965 relatou um tempo de execução de 0,02 minutos para uma DFT complexa de tamanho 2048 em um IBM 7094 (provavelmente em precisão simples de 36 bits, ~8 dígitos).[3] Ajustando o tempo pelo número de operações, isso corresponde aproximadamente a um fator de aceleração de cerca de 800.000 (para colocar o tempo para o cálculo manual em perspectiva, 140 minutos para o tamanho 64 corresponde a uma média de no máximo 16 segundos por operação de ponto flutuante, cerca de 20% dos quais são multiplicações).
Pseudocódigo
Em pseudocódigo, o procedimento abaixo poderia ser escrito:
X0,...,N−1 ← ditfft2(x, N, s): # DFT de (x0, xs, x2s, ..., x(N-1)s):
if N = 1 then
X0 ← x0 # caso base trivial da DFT de tamanho 1
else
X0,...,N/2−1 ← ditfft2(x, N/2, 2s) # DFT de (x0, x2s, x4s, ..., x(N-2)s)
XN/2,...,N−1 ← ditfft2(x+s, N/2, 2s) # DFT de (xs, xs+2s, xs+4s, ..., x(N-1)s)
for k = 0 to (N/2)-1 do # combinar as DFTs das duas metades
p ← Xk
q ← exp(−2πi/N k) Xk+N/2
Xk ← p + q
Xk+N/2 ← p − q
end for
end if
Aqui, ditfft2(x,N,1), calcula X=DFT(x) em um vetorseparado, usando uma FFT DIT de base 2, onde N é uma potência inteira de 2 e s=1 é o passo do vetor de entrada x. x+s indica o vetor que começa em xs.
(Os resultados estão na ordem correta em X e nenhuma outra permutação de reversão de bits é necessária; a frequentemente mencionada necessidade de um estágio separado de reversão de bits só surge em certos algoritmos in-place, como descrito abaixo.)
Implementações de FFT de alto desempenho fazem muitas modificações na implementação de tal algoritmo em comparação com este pseudocódigo simples. Por exemplo, pode-se usar um caso base maior que N=1 para amortizar a sobrecarga da recursão, os fatores de torção (twiddle factors) podem ser pré-computados, e radices maiores são frequentemente usados por motivos de cache; essas e outras otimizações, em conjunto, podem melhorar o desempenho em uma ordem de magnitude ou mais. (Em muitas implementações de livros didáticos, a recursão em profundidade é eliminada em favor de uma abordagem não recursiva em largura, embora se argumente que a recursão em profundidade oferece melhor localidade de memória.[6][7]) Várias dessas ideias são descritas em mais detalhes abaixo.
![{\displaystyle \exp[-2\pi ik/N]}](./_assets_/eb734a37dd21ce173a46342d1cc64c92/4d3237d9b3ed8e80ddaf135303aba19510130fa8.svg)
Ideia
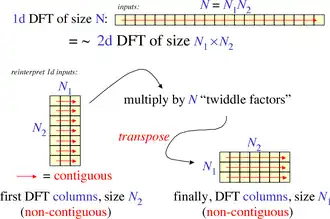
De forma mais geral, os algoritmos de Cooley–Tukey reexpressam recursivamente uma DFT de tamanho composto N = N1N 2 como:
- Realize N1 DFTs de tamanho N2.
- Multiplique pelas raízes complexas da unidade (geralmente chamadas de fatores de torção - twiddle factors).
- Realize N2 DFTs de tamanho N1.
Normalmente, N1 ou N2 é um fator pequeno (não necessariamente primo), chamado de radix (que pode diferir entre os estágios da recursão). Se N1 for o radix, é chamado de algoritmo de dizimação no tempo (DIT), enquanto se N2 for o radix, é de dizimação na frequência (DIF, também chamado de algoritmo de Sande–Tukey). A versão apresentada acima era um algoritmo radix-2 DIT (DIT de base 2); na expressão final, a fase que multiplica a transformada ímpar é o fator de rotação (twiddle factors), e a combinação +/- (borboleta) das transformadas pares e ímpares é uma DFT de tamanho 2. (A pequena DFT do radix às vezes é conhecida como "borboleta", assim chamada por causa do formato do diagrama de fluxo de dados para o caso radix-2.)
Variações
Existem muitas outras variações do algoritmo de Cooley-Tukey. Implementações de base mista (mixed-radix) lidam com tamanhos compostos com uma variedade de fatores (tipicamente pequenos) além de dois, geralmente (mas nem sempre) empregando o algoritmo O(N²) para os casos base primos da recursão (também é possível empregar um algoritmo N log N para os casos base primos, como o algoritmo de Rader ou o algoritmo de Bluestein). A abordagem split radix combina as bases 2 e 4, explorando o fato de que a primeira transformação da base 2 não requer fator de rotação (twiddle factor), a fim de alcançar o que foi por muito tempo a menor contagem de operações aritméticas conhecida para tamanhos de potência de dois, embora variações recentes alcancem uma contagem ainda menor. (Em computadores atuais, o desempenho é determinado mais por considerações de cache e pipeline da CPU do que por contagens de operações estritas; implementações de FFT bem otimizadas frequentemente empregam bases maiores e/ou transformadas de caso base codificadas de tamanho considerável).[8]
Outra maneira de ver o algoritmo de Cooley-Tukey é que ele reexpressa uma DFT unidimensional de tamanho N como uma DFT bidimensional N1 por N2 (mais inversões), onde a matriz de saída é transposta. O resultado líquido de todas essas transposições, para um algoritmo de base 2, corresponde a uma inversão de bits dos índices de entrada (DIF) ou saída (DIT). Se, em vez de usar uma base pequena, empregarmos uma base de √N e transposições explícitas das matrizes de entrada e saída, ele é chamado de algoritmo FFT de quatro etapas (ou seis etapas, dependendo do número de transposições), inicialmente proposto para melhorar a localidade de memória, por exemplo, para otimização de cache ou operação fora do núcleo, e posteriormente demonstrado como um algoritmo otimizado para ignorar o cache.
A fatoração geral de Cooley-Tukey reescreve os índices k e n como e , respectivamente, onde os índices ka e na variam de 0 a Na-1 (para a igual a 1 ou 2). Ou seja, reindexa a entrada (n) e a saída (k) como matrizes bidimensionais N1 por N2 em ordem de coluna e linha, respectivamente; a diferença entre essas indexações é uma transposição, como mencionado acima. Quando essa reindexação é substituída na fórmula DFT para nk, o termo de cruzamento desaparece (seu exponencial é igual a um), e os termos restantes resultam em:



-
- .

![{\displaystyle =\sum _{n_{1}=0}^{N_{1}-1}\left[e^{-{\frac {2\pi i}{N_{1}N_{2}}}n_{1}k_{2}}\right]\left(\sum _{n_{2}=0}^{N_{2}-1}x_{N_{1}n_{2}+n_{1}}e^{-{\frac {2\pi i}{N_{2}}}n_{2}k_{2}}\right)e^{-{\frac {2\pi i}{N_{1}}}n_{1}k_{1}}}](./_assets_/eb734a37dd21ce173a46342d1cc64c92/a455425257070160181227f7385f8820eb6238d4.svg)

onde cada soma interna é uma DFT de tamanho N2, cada soma externa é uma DFT de tamanho N1, e o termo entre colchetes [...] é o fator de rotação (twiddle factors).
Uma base arbitrária r (bem como bases mistas) pode ser empregada, como demonstrado por Cooley e Tukey[3] e por Gauss (que deu exemplos de passos de base 3 e base 6). Cooley e Tukey originalmente assumiram que a radix-butterfly requeria trabalho O(r2) e, portanto, calcularam a complexidade para uma base r como sendo O(r2 N/r logrN) = O(N log2(N) r/log2r); calculando os valores de r/log2r para valores inteiros de r de 2 a 12, a base ótima é encontrada como sendo 3 (o inteiro mais próximo de e, que minimiza r/log2r).[3] Esta análise estava errada, no entanto: a radix-butterfly também é uma DFT e pode ser realizada por meio de um algoritmo FFT em O(r log r) operações, portanto a base r na verdade se cancela na complexidade O(r log(r) N/r logrN), e o r ótimo é determinado por considerações mais complexas. Na prática, valores de r bastante grandes (32 ou 64) são importantes para explorar efetivamente, por exemplo, o grande número de registradores de processador em processadores modernos,[8] e até mesmo um radix ilimitado r =√N também atinge a complexidade O(N log N) e tem vantagens teóricas e práticas para N grande, como mencionado acima.
Reordenação de dados, inversão de bits e algoritmos in-place
Embora a fatoração do tipo Cooley-Tukey da DFT, acima, se aplique de alguma forma a todas as implementações do algoritmo, existe uma diversidade muito maior nas técnicas para ordenar e acessar os dados em cada estágio da FFT. De especial interesse é o problema de construir um algoritmo in-place que sobrescreva sua entrada com seus dados de saída usando apenas armazenamento auxiliar de O(1).
A técnica de reordenação mais conhecida envolve a inversão explícita de bits para algoritmos radix-2 in-place. A inversão de bits é a permutação na qual os dados em um índice n, escritos em binário com os digitos b₄b₃b₂b₁b₀ (por exemplo, 5 dígitos para N= 32 entradas), são alocados para o índice com os dígitos invertidos b₀b₁b₂b₃b₄. Considere o último estágio de um algoritmo radix-2 DIT como o apresentado acima, onde a saída é escrita in-place sobre a entrada: quando e são combinados com uma DFT de tamanho 2, esses dois valores são sobrescritos pelas saídas. No entanto, os dois valores de saída devem ir na primeira e na segunda metade do arranjo de saída, correspondendo ao bit mais significativo b4 (para N=32); enquanto as duas entradas e estão intercaladas nos elementos pares e ímpares, correspondendo ao bit menos significativo b0. Assim, para obter a saída no local correto, b0 deve substituir b4 e o índice passa a ser b0b4b3b2b1. E para o próximo estágio recursivo, esses 4 bits menos significativos passarão a ser b1b4b3b2, se você incluir todos os estágios recursivos de um algoritmo radix-2 DIT, todos os bits devem ser invertidos e, portanto, é necessário pré-processar a entrada (ou pós-processar a saída) com uma inversão de bits para obter a saída na ordem correta. (Se cada subtransformação de tamanho N/2 operar em dados contíguos, a entrada DIT é pré-processada por inversão de bits). Correspondentemente, se você executar todas as etapas na ordem inversa, obterá um algoritmo DIF de base 2 com inversão de bits no pós-processamento (ou pré-processamento, respectivamente).
O logaritmo (log) usado neste algoritmo é um logaritmo de base 2.
O seguir está o pseudocódigo para o algoritmo FFT iterativo radix-2 implementado usando permutação de inversão de bits.[9]
algorithm iterative-fft is
input: Vetor a de n valores complexos onde n é uma potência de 2.
output: Vetor A, a DFT de a.
bit-reverse-copy(a, A)
n ← a.length
for s = 1 to log(n) do
m ← 2s
ωm ← exp(−2πi/m)
for k = 0 to n-1 by m do
ω ← 1
for j = 0 to m/2 – 1 do
t ← ω A[k + j + m/2]
u ← A[k + j]
A[k + j] ← u + t
A[k + j + m/2] ← u – t
ω ← ω ωm
return A
O procedimento de cópia reversa de bits pode ser implementado da seguinte forma.
algorithm bit-reverse-copy(a,A) is
input: Vetor a de n valores complexos, onde n é uma potência de 2.
output: Array A of size n.
n ← a.length
for k = 0 to n – 1 do
A[rev(k)] := a[k]
Alternativamente, algumas aplicações (como a convolução) funcionam igualmente bem com dados com bits invertidos, permitindo realizar transformações diretas, processamento e, em seguida, transformações inversas, tudo sem inversão de bits, para produzir resultados finais na ordem natural.
No entanto, muitos usuários da FFT preferem saídas em ordem natural, e um estágio separado e explícito de inversão de bits pode ter um impacto não desprezível no tempo de computação,[8] embora a inversão de bits possa ser feita em tempo O(N) e tenha sido objeto de muita pesquisa.[10][11][12] Além disso, embora a permutação seja uma inversão de bits no caso de base 2, ela é mais geralmente uma inversão de dígitos arbitrária (mistas) para o caso de bases mistas, e os algoritmos de permutação tornam-se mais complicados de implementar. Ademais, em muitas arquiteturas de hardware, é desejável reordenar os estágios intermediários do algoritmo FFT para que operem em elementos de dados consecutivos (ou pelo menos mais localizados). Com esse objetivo, vários esquemas de implementação alternativos foram desenvolvidos para o algoritmo de Cooley-Tukey que não exigem inversão de bits separada e/ou envolvem permutações adicionais em estágios intermediários.
O problema se simplifica bastante se estiver em memória separada (out-of-place): a matriz de saída é diferente da matriz de entrada ou, equivalentemente, uma matriz auxiliar de tamanho igual está disponível. O algoritmo[13] executa cada etapa da FFT em memória separada, tipicamente escrevendo de um lado para o outro entre dois arrays, transpondo um "dígito" dos índices a cada etapa, e tem sido especialmente popular em arquiteturas SIMD.[14] Vantagens SIMD ainda maiores (mais acessos consecutivos) foram propostas para o algoritmo de Pease,[15] que também reordena out-of-place a cada etapa, mas esse método requer inversão de bits/dígitos separada e armazenamento O(N log N). Também é possível aplicar diretamente a definição de fatoração de Cooley-Tukey com recursão explícita (em profundidade) e bases pequenas, o que produz saída out-of-place em ordem natural sem uma etapa de permutação separada (como no pseudocódigo acima) e pode-se argumentar que possui benefícios de localidade independentes de cache em sistemas com memória hierárquica.[7][8][16]
Uma estratégia típica para algoritmos in-place sem armazenamento auxiliar e sem passagens separadas de inversão de dígitos envolve pequenas transposições de matriz (que trocam pares individuais de dígitos) em estágios intermediários, que podem ser combinadas com borboletas de radix para reduzir o número de iterações sobre os dados.[8][17][18][19][20]
Referências
- ↑ Gauss, Carl Friedrich (1866). «Theoria interpolationis methodo nova tractata». Nachlass (Unpublished manuscript). Col: Werke (em latim e alemão). 3. Göttingen, Germany: Königlichen Gesellschaft der Wissenschaften zu Göttingen. pp. 265–303
- ↑ a b c Heideman, M. T., D. H. Johnson, and C. S. Burrus, "Gauss and the history of the fast Fourier transform," IEEE ASSP Magazine, 1, (4), 14–21 (1984)
- ↑ a b c d e Cooley, James W.; Tukey, John W. (1965). «An algorithm for the machine calculation of complex Fourier series». Mathematics of Computation. 19 (90): 297–301. JSTOR 2003354. doi:10.2307/2003354
- ↑ Cooley, James W.; Lewis, Peter A. W.; Welch, Peter D. (1967). «Historical notes on the fast Fourier transform» (PDF). IEEE Transactions on Audio and Electroacoustics. 15 (2): 76–79. CiteSeerX 10.1.1.467.7209. doi:10.1109/tau.1967.1161903
- ↑ Rockmore, Daniel N., Comput. Sci. Eng. 2 (1), 60 (2000). The FFT — an algorithm the whole family can use Special issue on "top ten algorithms of the century "Barry A. Cipra. «The Best of the 20th Century: Editors Name Top 10 Algorithms» (PDF). SIAM News. 33 (4). Consultado em 31 de março de 2009. Cópia arquivada (PDF) em 7 de abril de 2009
- ↑ S. G. Johnson and M. Frigo, "Implementing FFTs in practice," in Fast Fourier Transforms (C. S. Burrus, ed.), ch. 11, Rice University, Houston TX: Connexions, September 2008.
- ↑ a b Singleton, Richard C. (1967). «On computing the fast Fourier transform». Commun. ACM. 10 (10): 647–654. doi:10.1145/363717.363771
- ↑ a b c d e Frigo, M.; Johnson, S. G. (2005). «The Design and Implementation of FFTW3» (PDF). Proceedings of the IEEE. 93 (2): 216–231. Bibcode:2005IEEEP..93..216F. CiteSeerX 10.1.1.66.3097. doi:10.1109/JPROC.2004.840301
- ↑ Cormen, Thomas H.; Leiserson, Charles; Rivest, Ronald; Stein, Clifford (2009). Introduction to algorithms 3rd ed. Cambridge, Mass.: MIT Press. pp. 915–918. ISBN 978-0-262-03384-8
- ↑ Karp, Alan H. (1996). «Bit reversal on uniprocessors». SIAM Review. 38 (1): 1–26. CiteSeerX 10.1.1.24.2913. JSTOR 2132972. doi:10.1137/1038001
- ↑ Carter, Larry; Gatlin, Kang Su (1998). «Towards an optimal bit-reversal permutation program». Proceedings 39th Annual Symposium on Foundations of Computer Science (Cat. No.98CB36280). [S.l.: s.n.] pp. 544–553. ISBN 978-0-8186-9172-0. doi:10.1109/SFCS.1998.743505
- ↑ Rubio, M.; Gómez, P.; Drouiche, K. (2002). «A new superfast bit reversal algorithm». International Journal of Adaptive Control and Signal Processing. 16 (10): 703–707. doi:10.1002/acs.718
- ↑ P. N. Swarztrauber, FFT algorithms for vector computers, Parallel Computing vol. 1, 45–63 (1984).
- ↑ Swarztrauber, P. N. (1982). «Vectorizing the FFTs». In: Rodrigue. Parallel Computations. New York: Academic Press. pp. 51–83. ISBN 978-0-12-592101-5
- ↑ Pease, M. C. (1968). «An adaptation of the fast Fourier transform for parallel processing». J. ACM. 15 (2): 252–264. doi:10.1145/321450.321457
- ↑ Frigo, Matteo; Johnson, Steven G. «FFTW» A free (GPL) C library for computing discrete Fourier transforms in one or more dimensions, of arbitrary size, using the Cooley–Tukey algorithm
- ↑ Johnson, H. W.; Burrus, C. S. (1984). «An in-place in-order radix-2 FFT». Proc. ICASSP: 28A.2.1–28A.2.4
- ↑ Temperton, C. (1991). «Self-sorting in-place fast Fourier transform». SIAM Journal on Scientific and Statistical Computing. 12 (4): 808–823. doi:10.1137/0912043
- ↑ Qian, Z.; Lu, C.; An, M.; Tolimieri, R. (1994). «Self-sorting in-place FFT algorithm with minimum working space». IEEE Transactions on Signal Processing. 52 (10): 2835–2836. Bibcode:1994ITSP...42.2835Q. doi:10.1109/78.324749
- ↑ Hegland, M. (1994). «A self-sorting in-place fast Fourier transform algorithm suitable for vector and parallel processing». Numerische Mathematik. 68 (4): 507–547. CiteSeerX 10.1.1.54.5659. doi:10.1007/s002110050074
Links externos
- «Fast Fourier transform - FFT». Cooley-Tukey technique. Article. 10
- «KISSFFT». GitHub. 11 de fevereiro de 2022
- Dsplib no GitHub
- «Radix-2 Decimation in Time FFT Algorithm». Arquivado do original em 31 de outubro de 2017 «Алгоритм БПФ по основанию два с прореживанием по времени» (em russo)
- «Radix-2 Decimation in Frequency FFT Algorithm». Arquivado do original em 14 de novembro de 2017 «Алгоритм БПФ по основанию два с прореживанием по частоте» (em russo)