Rede neural convolucional
No contexto de inteligência artificial e aprendizagem de máquina, uma Rede Neural Convolucional (CNN do inglês Convolutional Neural network ou ConvNet) é uma classe de Rede Neural Artificial, do tipo feed-forward, que vem sendo aplicada com sucesso no processamento e análise de imagens digitais.[1]
A CNN usa uma variação de perceptrons multicamada desenvolvidos de modo a demandar o mínimo pré-processamento possível. Essas redes também são conhecidas como redes neurais artificiais invariantes a deslocamento (shift invariant) ou invariantes a espaço (space invariant), em ambos os casos representadas pela sigla em inglês SIANN.[2][3]
As redes convolucionais são inspiradas nos processos biológicos.[4] Nelas, o padrão de conectividade entre os neurônios é inspirado na organização do córtex visual dos animais. Neurônios corticais individuais respondem a estímulos apenas em regiões restritas do campo de visão, conhecidas como campos receptivos. Os campos receptivos de diferentes neurônios se sobrepõem parcialmente de forma a cobrir todo o campo de visão.
Uma CNN tende a demandar um nível mínimo de pré-processamento quando comparada a outros algoritmos de classificação de imagens.[5] Isso significa que a rede "aprende" os filtros que em um algoritmo tradicional precisariam ser implementados manualmente. Essa independência de um conhecimento a priori e do esforço humano no desenvolvimento de suas funcionalidades básicas pode ser considerada a maior vantagem de sua aplicação.
Esse tipo de rede é usada principalmente em reconhecimento de imagens e processamento de vídeo, embora já tenha sido aplicada com sucesso em experimentos envolvendo processamento de voz e linguagem natural.
Na saúde, usa-se esta metodologia com algoritmos específicos, recorrendo a um grande número de fotografias clínicas, para o diagnóstico da retinopatia diabética e do cancro da pele, com resultados muito precisos e comparáveis aos clínicos especializados.[6][7]
Arquitetura
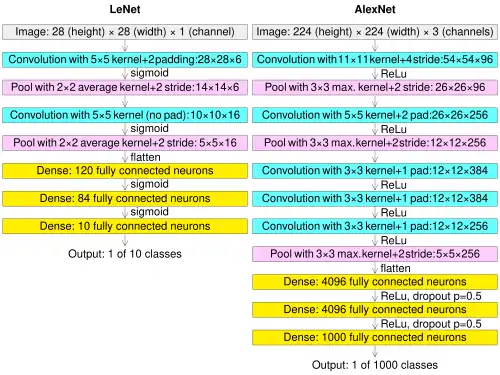
Uma rede neural convolucional consiste numa camada de entrada, camadas ocultas e uma camada de saída. Numa rede neural convolucional, as camadas ocultas incluem uma ou mais camadas que realizam convoluções. Tipicamente, isto inclui uma camada que executa um produto escalar do núcleo (kernel) de convolução com a matriz de entrada da camada. Este produto é geralmente o produto interno de Frobenius, e a sua função de ativação é comumente a ReLU. À medida que o núcleo de convolução desliza ao longo da matriz de entrada da camada, a operação de convolução gera um mapa de características (feature map), que por sua vez contribui para a entrada da camada seguinte. Isto é seguido por outras camadas, tais como camadas de agrupamento (pooling), camadas totalmente conectadas e camadas de normalização. Aqui deve notar-se o quão próxima uma rede neural convolucional é de um filtro casado.[8]
Camadas convolucionais
Numa CNN, a entrada é um tensor com o formato:
(número de entradas) × (altura da entrada) × (largura da entrada) × (canais de entrada)
Após passar por uma camada convolucional, a imagem é abstraída para um mapa de características, também chamado de mapa de ativação, com o formato:
(número de entradas) × (altura do mapa de características) × (largura do mapa de características) × (canais do mapa de características).
As camadas convolucionais convoluem a entrada e passam o seu resultado para a camada seguinte. Isto é semelhante à resposta de um neurônio no córtex visual a um estímulo específico.[9] Cada neurônio convolucional processa dados apenas para o seu campo receptivo.

Embora as redes neurais feedforward totalmente conectadas possam ser usadas para aprender características e classificar dados, esta arquitetura é geralmente impraticável para entradas maiores (por ex., imagens de alta resolução), o que exigiria um número massivo de neurônios porque cada pixel é uma característica de entrada relevante. Uma camada totalmente conectada para uma imagem de tamanho 100 × 100 tem 10.000 pesos para cada neurônio na segunda camada. A convolução reduz o número de parâmetros livres, permitindo que a rede seja mais profunda. Por exemplo, o uso de uma região de pavimentação (tiling) de 5 × 5, cada uma com os mesmos pesos partilhados, requer apenas 25 neurônios. O uso de pesos partilhados significa que existem muito menos parâmetros, o que ajuda a evitar os problemas do desvanecimento e da explosão do gradiente vistos durante a retropropagação em redes neurais anteriores.
Para acelerar o processamento, as camadas convolucionais padrão podem ser substituídas por camadas convolucionais separáveis em profundidade (depthwise separable),[10] que são baseadas numa convolução em profundidade (depthwise) seguida por uma convolução ponto a ponto (pointwise). A convolução em profundidade é uma convolução espacial aplicada independentemente sobre cada canal do tensor de entrada, enquanto a convolução ponto a ponto é uma convolução padrão restrita ao uso de núcleos .

Camadas de pooling
As redes convolucionais podem incluir camadas de agrupamento (pooling) local e/ou global juntamente com as camadas convolucionais tradicionais. As camadas de pooling reduzem as dimensões dos dados combinando as saídas de aglomerados de neurônios numa camada num único neurônio na camada seguinte. O pooling local combina pequenos aglomerados, sendo comumente usados tamanhos de pavimentação como 2 × 2. O pooling global atua sobre todos os neurônios do mapa de características.[11] Existem dois tipos comuns de pooling em uso popular: máximo e médio. O max pooling (agrupamento máximo) usa o valor máximo de cada aglomerado local de neurônios no mapa de características,[12][13] enquanto o average pooling (agrupamento médio) usa o valor médio.
Camadas totalmente conectadas
As camadas totalmente conectadas conectam todos os neurônios numa camada a todos os neurônios noutra camada. É o mesmo que uma rede neural tradicional de perceptron multicamadas (MLP). Cada neurônio na camada totalmente conectada recebe entrada de todos os neurônios na camada anterior. Estas entradas são ponderadas e somadas com os vieses correspondentes, e depois passadas por uma função de ativação para realizar uma transformação não linear, gerando a saída. A matriz achatada (flattened) passa por uma camada totalmente conectada para classificar as imagens.
Campo receptivo
Nas redes neurais, cada neurônio recebe entrada de um certo número de localizações na camada anterior. Numa camada convolucional, cada neurônio recebe entrada de apenas uma área restrita da camada anterior, chamada de campo receptivo do neurônio. Tipicamente, a área é um quadrado (por ex., 5 por 5 neurônios). Enquanto que, numa camada totalmente conectada, o campo receptivo é a camada anterior inteira. Assim, em cada camada convolucional, cada neurônio recebe entrada de uma área maior na entrada original do que as camadas anteriores. Isso deve-se à aplicação repetida da convolução, que leva em consideração o valor de um pixel, bem como os seus pixels circundantes. Ao usar camadas dilatadas, o número de pixels no campo receptivo permanece constante, mas o campo é povoado de forma mais esparsa à medida que as suas dimensões crescem ao combinar o efeito de várias camadas.
Para manipular o tamanho do campo receptivo conforme desejado, existem algumas alternativas à camada convolucional padrão. Por exemplo, a convolução atrous ou dilatada expande o tamanho do campo receptivo sem aumentar o número de parâmetros, intercalando regiões visíveis e cegas.[14][15] Além disso, uma única camada convolucional dilatada pode compreender filtros com múltiplas razões de dilatação, tendo assim um tamanho de campo receptivo variável.[16]
Pesos
Cada neurônio numa rede neural calcula um valor de saída aplicando uma função específica aos valores de entrada recebidos do campo receptivo na camada anterior. A função que é aplicada aos valores de entrada é determinada por um vetor de pesos e um viés (tipicamente números reais). A aprendizagem consiste em ajustar iterativamente estes vieses e pesos.
Os vetores de pesos e vieses são chamados de filtros e representam características particulares da entrada (por ex., uma forma específica). Uma característica distintiva das CNNs é que muitos neurônios podem partilhar o mesmo filtro. Isto reduz a pegada de memória porque um único viés e um único vetor de pesos são usados em todos os campos receptivos que partilham esse filtro, em oposição a cada campo receptivo ter o seu próprio viés e ponderação vetorial.[17]
Deconvolucional
Uma rede neural deconvolucional é essencialmente o inverso de uma CNN. Consiste em camadas deconvolucionais e camadas de desagrupamento (unpooling).[18]
Uma camada deconvolucional é a transposta de uma camada convolucional. Especificamente, uma camada convolucional pode ser escrita como uma multiplicação por uma matriz, e uma camada deconvolucional é a multiplicação pela transposta dessa matriz.[19]
Uma camada de desagrupamento expande a camada. A camada de desagrupamento máximo (max-unpooling) é a mais simples, pois simplesmente copia cada entrada várias vezes. Por exemplo, uma camada de desagrupamento máximo de 2 por 2 é .
![{\displaystyle [x]\mapsto {\begin{bmatrix}x&x\\x&x\end{bmatrix}}}](./_assets_/eb734a37dd21ce173a46342d1cc64c92/ba907f707b81817e69c003905058b928e9097b86.svg)
As camadas de deconvolução são usadas em geradores de imagens. Por padrão, cria artefactos periódicos em padrão de tabuleiro de xadrez (checkerboard artifacts), que podem ser corrigidos por aumento de escala seguido de convolução (upscale-then-convolve).[20]
História
As CNNs são frequentemente comparadas com a forma como o cérebro consegue o processamento da visão nos organismos vivos.[21]
Campos receptivos no córtex visual
O trabalho de Hubel e Wiesel nas décadas de 1950 e 1960 mostrou que os córtexes visuais dos gatos contêm neurônios que respondem individualmente a pequenas regiões do campo visual. Desde que os olhos não estejam em movimento, a região do espaço visual dentro da qual os estímulos visuais afetam o disparo de um único neurônio é conhecida como o seu campo receptivo.[22] As células vizinhas têm campos receptivos semelhantes e sobrepostos. O tamanho e a localização do campo receptivo variam sistematicamente ao longo do córtex para formar um mapa completo do espaço visual. O córtex em cada hemisfério representa o campo visual contralateral.
O seu artigo de 1968 identificou dois tipos básicos de células visuais no cérebro:[23]
- células simples, cuja saída é maximizada por bordas retas com orientações particulares dentro do seu campo receptivo
- células complexas, que têm campos receptivos maiores, cuja saída é insensível à posição exata das bordas no campo.
Hubel e Wiesel também propuseram um modelo em cascata destes dois tipos de células para uso em tarefas de reconhecimento de padrões.[24][22]
Elementos analógicos de limiar de Fukushima num modelo de visão
Em 1969, Kunihiko Fukushima introduziu uma rede multicamadas de deteção de caraterísticas visuais, baseando-se nas investigações anteriores de Hubel e Wiesel. Descreveu-a nestes termos: "Todos os elementos presentes numa camada operam com a mesma matriz de coeficientes de conexão; tanto o posicionamento dos elementos como a sua rede de conexões mantêm-se homogeneamente distribuídos através de qualquer camada dada." Este é o núcleo central de uma rede convolucional, mas os pesos não foram treinados. No mesmo artigo, Fukushima também introduziu a função de ativação ReLU (unidade linear retificada).[25][26]
Neocognitron, a origem da arquitetura de CNN treinável
O "neocognitron" foi introduzido por Fukushima em 1980.[27] O neocognitron introduziu os dois tipos básicos de camadas:
- "Camada-S": uma camada de campo receptivo de pesos partilhados, mais tarde conhecida como camada convolucional, que contém unidades cujos campos receptivos cobrem um retalho (patch) da camada anterior. Um grupo de campo receptivo de pesos partilhados (um "plano" na terminologia do neocognitron) é frequentemente chamado de filtro, e uma camada tipicamente tem vários desses filtros.
- "Camada-C": uma camada de subamostragem (downsampling) que contém unidades cujos campos receptivos cobrem retalhos de camadas convolucionais anteriores. Tal unidade tipicamente calcula uma média ponderada das ativações das unidades no seu retalho, e aplica a inibição (normalização divisiva) agrupada a partir de um retalho um pouco maior e através de diferentes filtros numa camada, e aplica uma função de ativação de saturação. Os pesos dos retalhos são não negativos e não são treináveis no neocognitron original. A subamostragem e a inibição competitiva ajudam a classificar características e objetos em cenas visuais, mesmo quando os objetos são deslocados.
Vários algoritmos de aprendizado supervisionado e não supervisionado foram propostos ao longo das décadas para treinar os pesos de um neocognitron. Hoje, no entanto, a arquitetura da CNN é normalmente treinada através da retropropagação (backpropagation).
A função de ativação ReLU de Fukushima não foi usada no seu neocognitron uma vez que todos os pesos eram não negativos; em vez disso, foi usada a inibição lateral. A unidade retificadora tornou-se uma função de ativação muito popular para as CNNs e redes neurais profundas em geral.[28]
Convolução no tempo
O termo "convolução" surge inicialmente nas redes neurais num artigo de Toshiteru Homma, Les Atlas e Robert Marks II, na edição inaugural da Conference on Neural Information Processing Systems, no ano de 1987. No estudo, adotaram a convolução no tempo em vez da multiplicação para obter invariação de deslocamento (shift invariance), buscando paralelismos com os métodos usados nos filtros lineares invariantes no deslocamento (linear shift-invariant filters) da teoria do processamento de sinal, e demonstraram-no numa tarefa de reconhecimento de fala.[29] Eles sublinharam além disso que, no contexto de um sistema treinável a partir de dados, a convolução confunde-se fundamentalmente com a correlação, pois inverter a direção dos pesos não se reflete num desfecho final da função apreendida ("Por conveniência, denotamos * como correlação em vez de convolução. Note-se que a convolução de a(t) com b(t) é equivalente à correlação de a(-t) com b(t).").[29] Semelhante ao que eles fizeram, as atuais configurações de CNN comumente efetuam cálculos de correlação sob o título de convolução de forma a uniformizar e facilitar a designação.
Redes neurais com atraso de tempo
A rede neural com atraso de tempo (time delay neural network - TDNN) foi introduzida em 1987 por Alexander Waibel et al. para o reconhecimento de fonemas e foi uma rede convolucional precoce a exibir invariação de deslocamento.[30] Uma TDNN é uma rede neural convolucional 1D onde a convolução é executada ao longo do eixo de tempo dos dados. É a primeira CNN a utilizar a partilha de pesos em combinação com um treinamento por descida de gradiente, usando a retropropagação (backpropagation).[31] Assim, enquanto também usava uma estrutura piramidal como no neocognitron, ela realizava uma otimização global dos pesos em vez de uma local.[30]
As TDNNs são redes convolucionais que partilham pesos ao longo da dimensão temporal.[32] Permitem que os sinais de fala sejam processados de forma invariante no tempo. Em 1990, Hampshire e Waibel introduziram uma variante que realiza uma convolução bidimensional.[33] Dado que estas TDNNs operavam em espectrogramas, o sistema de reconhecimento de fonemas resultante era invariante a deslocamentos tanto de tempo como de frequência, tal como as imagens processadas por um neocognitron.
As TDNNs melhoraram o desempenho do reconhecimento de fala a longa distância.[34]
Reconhecimento de imagens com CNNs treinadas por descida de gradiente
Denker et al. (1989) desenharam um sistema de CNN 2D para reconhecer números de código postal (ZIP Code) manuscritos.[35] No entanto, a falta de um método de treinamento eficiente para determinar os coeficientes do núcleo das convoluções envolvidas significava que todos os coeficientes tinham que ser laboriosamente desenhados à mão.[36]
Seguindo os avanços no treinamento de CNNs 1D por Waibel et al. (1987), Yann LeCun et al. (1989)[36] usaram a retropropagação (backpropagation) para aprender os coeficientes do núcleo de convolução diretamente a partir de imagens de números manuscritos. A aprendizagem era assim totalmente automática, com melhor desempenho do que o desenho manual de coeficientes, e adequava-se a uma gama mais ampla de problemas de reconhecimento de imagens e tipos de imagens. Wei Zhang et al. (1988) usaram a retropropagação para treinar os núcleos de convolução de uma CNN para reconhecimento de alfabetos. O modelo foi chamado de rede neural de reconhecimento de padrões invariante no deslocamento, antes do nome CNN ter sido cunhado mais tarde no início da década de 1990. Wei Zhang et al. também aplicaram a mesma CNN sem a última camada totalmente conectada para segmentação de objetos de imagem médica (1991)[37] e deteção de cancro da mama em mamografias (1994).[38]
Esta abordagem tornou-se uma base da visão computacional moderna.
Agrupamento máximo (Max pooling)
Em 1990, Yamaguchi et al. introduziram o conceito de agrupamento máximo (max pooling), uma operação de filtragem fixa que calcula e propaga o valor máximo de uma dada região. Fizeram-no combinando TDNNs com max pooling para realizar um sistema de reconhecimento de palavras isoladas independente do locutor. No seu sistema, usaram várias TDNNs por palavra, uma para cada sílaba. Os resultados de cada TDNN sobre o sinal de entrada foram combinados usando max pooling e as saídas das camadas de pooling foram então passadas para as redes que executavam a classificação de palavras real.
Numa variante do neocognitron chamada cresceptron, em vez de usar a média espacial com inibição e saturação de Fukushima, J. Weng et al. em 1993 usaram o max pooling, onde uma unidade de subamostragem calcula o máximo das ativações das unidades no seu retalho,[39] introduzindo este método no campo da visão.
O agrupamento máximo é frequentemente usado em CNNs modernas.[40]
LeNet-5
A LeNet-5, uma rede convolucional pioneira de 7 níveis por LeCun et al. em 1995,[41] classifica números manuscritos em cheques digitalizados em imagens de 32×32 pixels. A capacidade de processar imagens de alta resolução requer redes neurais convolucionais maiores e com mais camadas, por isso esta técnica é limitada pela disponibilidade de recursos de computação.
O sistema superava claramente outras soluções comerciais para a leitura dos montantes em cheques da época (1995). Como resultado da integração e adoção desta tecnologia pelos sistemas de leitura de cheques da NCR, dezenas de milhões de cheques começaram a ser verificados numa base diária a partir de junho de 1996 em inúmeros balcões e estruturas do sistema bancário estadunidense.[42]
Rede neural invariante no deslocamento
Uma rede neural invariante no deslocamento foi proposta por Wei Zhang et al. para o reconhecimento de caracteres de imagem em 1988.Trata-se de um Neocognitron modificado mantendo apenas as interconexões convolucionais entre as camadas de características da imagem e a última camada totalmente conectada. O modelo foi treinado com retropropagação. O algoritmo de treinamento foi aperfeiçoado em 1991[43] para melhorar a sua capacidade de generalização. A arquitetura do modelo foi modificada removendo a última camada totalmente conectada e aplicada à segmentação de imagens médicas (1991)[37] e deteção automática de cancro da mama em mamografias (1994).[38]
Um modelo convolutivo diferente foi apresentado em 1988[44] concebido para uso no tratamento de correntes de sinal elétrico numa perspetiva deconvolutiva a aplicar numa única dimensão no espetro operatório dos exames de diagnóstico dos tecidos corporais com a eletromiografia. Uma readaptação desta mesma versão obteve a configuração que a transferiu para um estatuto análogo de operação no ano subsequente.[45][46]
Implementações em GPU
Embora as CNNs tenham sido inventadas na década de 1980, a sua descoberta na década de 2000 exigiu implementações rápidas em unidades de processamento gráfico (GPUs).
Em 2004, foi demonstrado por K. S. Oh e K. Jung que as redes neurais padrão podiam ser largamente aceleradas em GPUs. A implementação deles foi 20 vezes mais rápida do que uma implementação equivalente em CPU.[47] Em 2005, outro artigo também enfatizou o valor da GPGPU para o aprendizado de máquina.[48]
A primeira implementação em GPU de uma CNN foi descrita em 2006 por K. Chellapilla et al. A implementação deles foi 4 vezes mais rápida do que uma implementação equivalente em CPU.[49] No mesmo período, as GPUs também foram usadas para o treinamento não supervisionado de redes de crença profunda (deep belief networks).[50][51][52][53]
Em 2010, Dan Ciresan et al. no IDSIA treinaram redes profundas de alimentação para a frente (feedforward) em GPUs.[54] Em 2011, estenderam isso às CNNs, acelerando em 60 vezes em comparação com o treinamento em CPU.[55] Em 2011, a rede venceu um concurso de reconhecimento de imagens onde alcançou um desempenho sobre-humano pela primeira vez.[56] Em seguida, ganharam mais competições e alcançaram o estado da arte em vários benchmarks.[57][40]
Posteriormente, a AlexNet, uma CNN similar baseada em GPU por Alex Krizhevsky et al., venceu o ImageNet Large Scale Visual Recognition Challenge 2012.Foi um dos primeiros eventos catalisadores para o boom da IA.
Em comparação com o treinamento de CNNs utilizando GPUs, o CPU não beneficiou de grande ponderação neste aspeto em particular. (Viebke et al., 2019) encarrega-se da tarefa de paralelização computacional mediante a afetação das vias inerentes ao nível dos fios de instrução da sua CPU em concomitância com os requisitos SIMD cujos padrões de arquitetura viabilizavam a plataforma informática por eles enquadrada - o modelo computacional Intel Xeon Phi.[58][59]
Características distintivas
No passado, modelos tradicionais de perceptron multicamadas (MLP) eram usados para reconhecimento de imagens. No entanto, a conectividade total entre os nós causava a maldição da dimensionalidade e era computacionalmente intratável com imagens de alta resolução. Uma imagem de 1000×1000 pixels com canais de cores RGB possui 3 milhões de pesos por neurônio totalmente conectado, o que é alto demais para ser processado de forma viável e eficiente em larga escala.
Por exemplo, no CIFAR-10, as imagens têm apenas o tamanho de 32×32×3 (32 de largura, 32 de altura, 3 canais de cor), de modo que um único neurônio totalmente conectado na primeira camada oculta de uma rede neural comum teria 32*32*3 = 3.072 pesos. Uma imagem de 200×200, no entanto, levaria a neurônios com 200*200*3 = 120.000 pesos.
Além disso, tal arquitetura de rede não leva em consideração a estrutura espacial dos dados, tratando pixels de entrada que estão muito distantes da mesma forma que pixels que estão próximos uns dos outros. Isso ignora a localidade de referência em dados com uma topologia de grade (como imagens), tanto computacional como semanticamente. Assim, a conectividade total dos neurônios é um desperdício para propósitos como o reconhecimento de imagens, que são dominados por padrões de entrada espacialmente locais.
As redes neurais convolucionais são variantes dos perceptrons multicamadas, projetadas para emular o comportamento de um córtex visual. Estes modelos mitigam os desafios colocados pela arquitetura MLP ao explorar a forte correlação espacialmente local presente em imagens naturais. Ao contrário dos MLPs, as CNNs possuem as seguintes características distintivas:
- Volumes 3D de neurônios. As camadas de uma CNN possuem neurônios dispostos em 3 dimensões: largura, altura e profundidade.[60] Cada neurônio dentro de uma camada convolucional está conectado a apenas uma pequena região da camada anterior, chamada de campo receptivo. Tipos distintos de camadas, tanto conectadas localmente como totalmente, são empilhadas para formar uma arquitetura CNN.
- Conectividade local: seguindo o conceito de campos receptivos, as CNNs exploram a localidade espacial ao impor um padrão de conectividade local entre os neurônios de camadas adjacentes. A arquitetura garante assim que os "filtros" aprendidos produzam a resposta mais forte a um padrão de entrada espacialmente local. O empilhamento de muitas dessas camadas leva a filtros não lineares que se tornam cada vez mais globais (ou seja, responsivos a uma região maior do espaço de pixels), de modo que a rede primeiro cria representações de pequenas partes da entrada e, a partir delas, monta representações de áreas maiores.
- Pesos partilhados (Shared weights): Nas CNNs, cada filtro é replicado em todo o campo visual. Estas unidades replicadas partilham a mesma parametrização (vetor de pesos e viés) e formam um mapa de características. Isto significa que todos os neurônios numa dada camada convolucional respondem à mesma característica dentro do seu campo de resposta específico. A replicação de unidades desta forma permite que o mapa de ativação resultante seja equivariante sob deslocamentos das localizações das características de entrada no campo visual, ou seja, elas concedem equivariância translacional — dado que a camada tem um passo (stride) de um.
- Agrupamento (Pooling): Nas camadas de agrupamento de uma CNN, os mapas de características são divididos em sub-regiões retangulares, e as características em cada retângulo são independentemente subamostradas (down-sampled) para um único valor, comumente calculando a sua média ou valor máximo. Além de reduzir os tamanhos dos mapas de características, a operação de agrupamento concede um grau de invariância translacional local às características aí contidas, permitindo que a CNN seja mais robusta a variações nas suas posições.
Juntas, estas propriedades permitem que as CNNs alcancem uma melhor generalização em problemas de visão. A partilha de pesos reduz drasticamente o número de parâmetros livres aprendidos, diminuindo assim os requisitos de memória para executar a rede e permitindo o treinamento de redes maiores e mais poderosas.
Blocos de construção
Uma arquitetura CNN é formada por uma pilha de camadas distintas que transformam o volume de entrada num volume de saída (por ex., contendo as pontuações de classe) através de uma função diferenciável. Alguns tipos distintos de camadas são comumente usados. Estes são discutidos mais adiante.
Camada convolucional

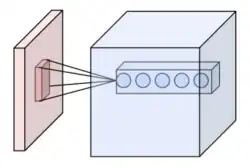
A camada convolucional é o bloco de construção central de uma CNN. Os parâmetros da camada consistem num conjunto de filtros aprendíveis (ou núcleos), que têm um pequeno campo receptivo, mas estendem-se por toda a profundidade do volume de entrada. Durante a passagem à frente (forward pass), cada filtro é convoluído através da largura e altura do volume de entrada, calculando o produto escalar entre as entradas do filtro e a entrada, produzindo um mapa de ativação bidimensional desse filtro. Como resultado, a rede aprende filtros que se ativam quando detetam algum tipo específico de característica nalguma posição espacial na entrada.[61][62]
O empilhamento dos mapas de ativação para todos os filtros ao longo da dimensão de profundidade forma o volume de saída completo da camada de convolução. Cada entrada no volume de saída pode, portanto, também ser interpretada como a saída de um neurônio que olha para uma pequena região na entrada. Cada entrada num mapa de ativação usa o mesmo conjunto de parâmetros que definem o filtro.
O aprendizado autossupervisionado foi adaptado para uso em camadas convolucionais através do uso de retalhos (patches) esparsos com uma alta proporção de máscara e uma camada de normalização de resposta global.[carece de fontes]
Conectividade local
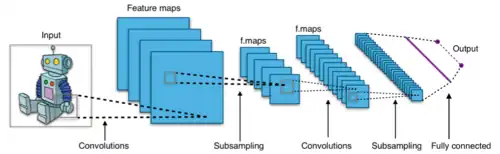
Ao lidar com entradas de alta dimensão, como imagens, é impraticável conectar neurônios a todos os neurônios do volume anterior, porque tal arquitetura de rede não leva em conta a estrutura espacial dos dados. As redes convolucionais exploram a correlação espacialmente local ao impor um padrão de conectividade local esparsa entre os neurônios de camadas adjacentes: cada neurônio está conectado a apenas uma pequena região do volume de entrada.
A extensão desta conectividade é um hiperparâmetro chamado de campo receptivo do neurônio. As conexões são locais no espaço (ao longo da largura e altura), mas estendem-se sempre ao longo de toda a profundidade do volume de entrada. Tal arquitetura garante que os filtros aprendidos produzam a resposta mais forte a um padrão de entrada espacialmente local.[63]
Arranjo espacial
Três hiperparâmetros controlam o tamanho do volume de saída da camada convolucional: a profundidade, o passo (stride) e o tamanho do preenchimento (padding):
- A profundidade do volume de saída controla o número de neurônios numa camada que se conectam à mesma região do volume de entrada. Estes neurônios aprendem a ativar-se para diferentes características na entrada. Por exemplo, se a primeira camada convolucional recebe a imagem original (raw image) como entrada, então diferentes neurônios ao longo da dimensão de profundidade podem ativar-se na presença de várias bordas orientadas, ou manchas de cor.
- O passo controla como as colunas de profundidade em torno da largura e altura são alocadas. Se o passo for 1, então movemos os filtros um pixel de cada vez. Isto leva a campos receptivos fortemente sobrepostos entre as colunas e a grandes volumes de saída. Para qualquer número inteiro , um passo S significa que o filtro é transladado S unidades de cada vez por saída. Na prática, é raro. Um passo maior significa uma menor sobreposição de campos receptivos e dimensões espaciais menores do volume de saída.[64]
- Por vezes, é conveniente preencher a entrada com zeros (ou outros valores, como a média da região) na borda do volume de entrada. O tamanho deste preenchimento é um terceiro hiperparâmetro. O preenchimento fornece controle sobre o tamanho espacial do volume de saída. Em particular, por vezes é desejável preservar exatamente o tamanho espacial do volume de entrada, o que é comumente referido como preenchimento "igual" (same padding).



O tamanho espacial do volume de saída é uma função do tamanho do volume de entrada , do tamanho do campo do núcleo dos neurônios da camada convolucional, do passo e da quantidade de preenchimento com zeros na borda. O número de neurônios que "cabem" num dado volume é então:





Se este número não for um número inteiro, então os passos estão incorretos e os neurônios não podem ser dispostos lado a lado para caber em todo o volume de entrada de forma simétrica. Em geral, definir o preenchimento com zeros como quando o passo é garante que o volume de entrada e o volume de saída terão o mesmo tamanho espacialmente. No entanto, nem sempre é totalmente necessário usar todos os neurônios da camada anterior. Por exemplo, o criador de uma rede neural pode decidir usar apenas uma porção do preenchimento.


Partilha de parâmetros
Um esquema de partilha de parâmetros é usado em camadas convolucionais para controlar o número de parâmetros livres. Baseia-se no pressuposto de que se for útil calcular uma característica de retalho (patch feature) nalguma posição espacial, então também deve ser útil calculá-la noutras posições. Denotando uma única fatia bidimensional de profundidade como uma fatia de profundidade, os neurônios em cada fatia de profundidade são constrangidos a usar os mesmos pesos e viés.
Como todos os neurônios numa única fatia de profundidade partilham os mesmos parâmetros, a passagem para a frente em cada fatia de profundidade da camada convolucional pode ser calculada como uma convolução dos pesos do neurônio com o volume de entrada.[65] Portanto, é comum referir-se aos conjuntos de pesos como um filtro (ou um núcleo), o qual é convoluído com a entrada. O resultado desta convolução é um mapa de ativação, e o conjunto de mapas de ativação para cada filtro diferente é empilhado ao longo da dimensão de profundidade para produzir o volume de saída. A partilha de parâmetros contribui para a invariância de translação da arquitetura CNN.
Por vezes, a suposição de partilha de parâmetros pode não fazer sentido. É o caso, em especial, de quando as imagens de entrada numa CNN têm alguma estrutura centrada específica, relativamente à qual se espera que se apreendam características diametralmente distintas de localizações de espaço também elas separadas umas das outras. Uma exemplificação pragmática acontece quando as entradas (inputs) são os próprios rostos de indivíduos os quais acabaram centrados no material visível: prevemos logicamente que, do tratamento formativo na rede em causa, resultará a apreensão e a captação inerente nos distintos compartimentos visuais da foto quer de detalhes característicos em concreto do pêlo/cabelo em causa bem como pormenores relativos especificamente aos globos oculares do rosto. Neste caso, é comum flexibilizar o esquema de partilha de parâmetros e, em vez disso, chamar simplesmente à camada uma "camada conectada localmente". Nesta camada, os parâmetros dos núcleos convolucionais não são partilhados. Em vez disso, a rede aprende pesos e vieses independentes para cada localização espacial. Isso permite que cada localização tenha a sua própria capacidade de aprendizagem de características, tornando-a mais adequada para lidar com imagens com estruturas centrais distintas ou características irregulares.
Camada de pooling
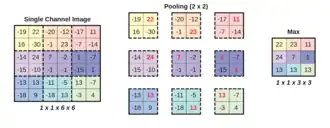
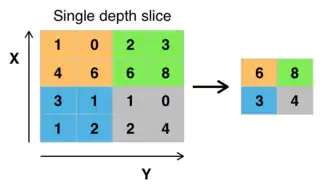
Outro conceito importante das CNNs é o agrupamento (pooling), que é usado como uma forma de subamostragem não linear. O agrupamento fornece subamostragem porque reduz as dimensões espaciais (altura e largura) dos mapas de características de entrada, retendo as informações mais importantes. Existem várias funções não lineares para implementar o agrupamento, em que o agrupamento máximo (max pooling) e o agrupamento médio (average pooling) são os mais comuns. O agrupamento agrega informações de pequenas regiões da entrada, criando partições do mapa de características de entrada, tipicamente usando uma janela de tamanho fixo (como 2x2) e aplicando um passo (frequentemente 2) para mover a janela através da entrada.[66] Note-se que sem usar um passo maior do que 1, o agrupamento não realizaria a subamostragem, pois simplesmente moveria a janela de agrupamento através da entrada um passo de cada vez, sem reduzir o tamanho do mapa de características. Em outras palavras, o passo é o que realmente causa a subamostragem, ao determinar o quanto a janela de agrupamento se move sobre a entrada.
Intuitivamente, a localização exata de uma característica é menos importante do que a sua localização aproximada em relação a outras características. Esta é a ideia por trás do uso do agrupamento em redes neurais convolucionais. A camada de agrupamento serve para reduzir progressivamente o tamanho espacial da representação, para reduzir o número de parâmetros, a pegada de memória e a quantidade de computação na rede e, portanto, para controlar também o sobreajuste (overfitting). Isso é conhecido como subamostragem. É comum inserir periodicamente uma camada de agrupamento entre camadas convolucionais sucessivas (cada uma tipicamente seguida por uma função de ativação, como uma camada ReLU) numa arquitetura de CNN.[61]:460–461 Embora as camadas de agrupamento contribuam para a invariância de translação local, elas não fornecem invariância de translação global numa CNN, a menos que seja usada uma forma de agrupamento global.[67] A camada de agrupamento comumente opera de forma independente em cada profundidade, ou fatia, da entrada e redimensiona-a espacialmente. Uma forma muito comum de agrupamento máximo é uma camada com filtros de tamanho 2×2, aplicada com um passo de 2, que subamostra cada fatia de profundidade na entrada por 2 tanto na largura como na altura, descartando 75% das ativações: Neste caso, cada operação de máximo é efetuada sobre 4 números. A dimensão de profundidade permanece inalterada (isso também é verdade para outras formas de agrupamento).

Além do agrupamento máximo, as unidades de agrupamento podem usar outras funções, tais como o agrupamento médio ou agrupamento de norma-ℓ2. O agrupamento médio era frequentemente utilizado no passado, mas recentemente caiu em desuso em relação ao agrupamento máximo, que geralmente apresenta um melhor desempenho prático.[68]
Devido aos efeitos da rápida redução espacial do tamanho da representação, há uma tendência recente para o uso de filtros menores[69] ou de se descartar totalmente as camadas de agrupamento.[70]
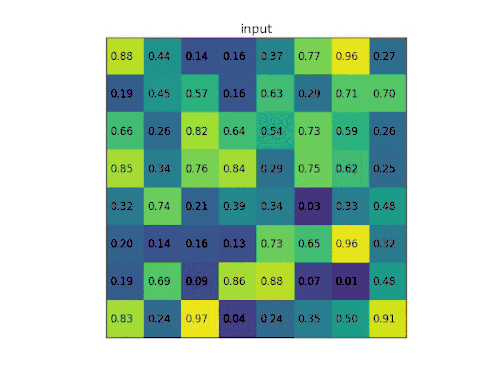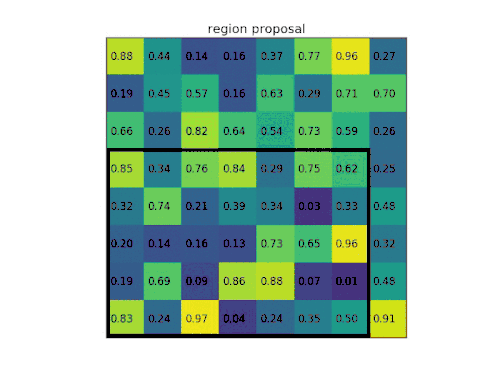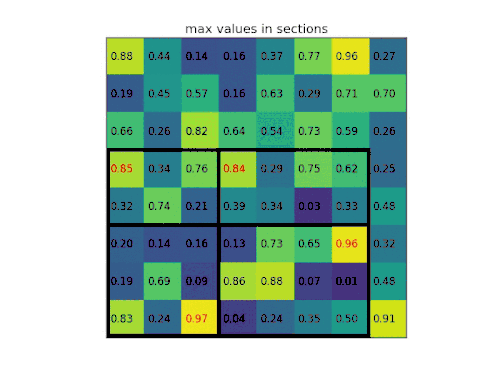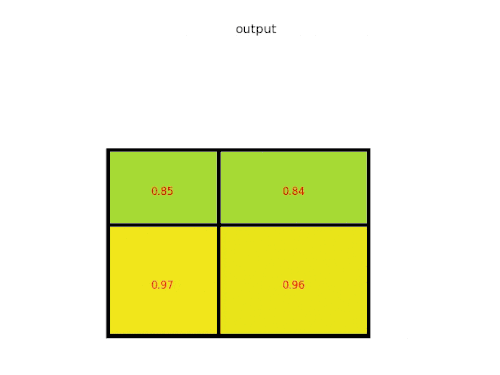
Agrupamento máximo de canais
Uma camada de operação de agrupamento máximo de canais (channel max pooling - CMP) conduz a operação de agrupamento máximo (MP) ao longo do lado do canal entre as posições correspondentes dos mapas de características consecutivos com a finalidade de eliminar a informação redundante. O CMP faz com que as características significativas se reúnam em menos canais, o que é importante para a classificação de imagens com granulação fina (fine-grained) que necessita de características mais discriminativas. Ao mesmo tempo, outra vantagem da operação CMP é tornar o número de canais de mapas de características menor antes de se ligar à primeira camada totalmente conectada (FC). Semelhante à operação MP, denotamos os mapas de características de entrada e os mapas de características de saída de uma camada CMP como F ∈ R(C×M×N) e C ∈ R(c×M×N), respectivamente, onde C e c são os números de canal dos mapas de características de entrada e saída, M e N são as larguras e a altura dos mapas de características, respetivamente. Note-se que a operação CMP altera apenas o número de canais dos mapas de características. A largura e a altura dos mapas de características não são alteradas, o que é diferente da operação MP.[71]
Camada ReLU
ReLU é a abreviatura de unidade linear retificada. Foi proposta por Alston Householder em 1941,[74] e usada na CNN por Kunihiko Fukushima em 1969. A ReLU aplica a função de ativação não saturante .[75] Remove efetivamente valores negativos de um mapa de ativação ajustando-os a zero.[76] Introduz a não linearidade à função de decisão e à rede global sem afetar os campos receptivos das camadas de convolução.

Em 2011, Xavier Glorot, Antoine Bordes e Yoshua Bengio descobriram que a ReLU permite um melhor treinamento de redes mais profundas,[77] em comparação com as funções de ativação amplamente usadas antes de 2011.
Outras funções também podem ser usadas para aumentar a não linearidade, por exemplo, a função saturante de tangente hiperbólica , , e a função sigmoide . A ReLU é frequentemente preferida a outras funções porque treina a rede neural várias vezes mais depressa sem uma penalização significativa na exatidão da generalização.[78]



Camada totalmente conectada
Após várias camadas convolucionais e de agrupamento máximo, a classificação final é feita através de camadas totalmente conectadas. Os neurônios numa camada totalmente conectada têm conexões com todas as ativações na camada anterior, como visto em redes neurais artificiais normais (não convolucionais). As suas ativações podem assim ser calculadas como uma transformação afim, com multiplicação de matrizes seguida de um desvio de viés (adição de vetores de um termo de viés aprendido ou fixo).
Camada de perda
A "camada de perda" ou "função de perda", exemplifica de que forma o treinamento censura uma incongruência existente relativamente à diferença encontrada avaliando e confrontando entre as previsões fornecidas na operação das infraestruturas de análise elaboradas pela rede com as conclusões preexistentes nas premissas avaliatórias com fundamento prévio no conhecimento da correspondência tida por verdadeira e válida com suporte em dados físicos materiais (ao longo de exercícios atinentes a aprendizagens orientadas baseadas ou auxiliadas mediante o escrutínio e vigilância externa). Inúmeras funções de perdas diversificadas assumem o caráter da sua conveniência condicionado, na sua exequibilidade, segundo as tarefas e a especificidade exigida nestas mesmas.
A função de perda Softmax é usada para prever uma única classe de K classes mutuamente exclusivas.[79] A perda de entropia cruzada da sigmoide é usada para prever K valores de probabilidade independentes no intervalo de . A perda euclidiana é usada para regredir para rótulos de valores contidos no universo abrangente à formulação traduzida formalmente por todo e qualquer número real expresso do seguinte modo: .
![{\displaystyle [0,1]}](./_assets_/eb734a37dd21ce173a46342d1cc64c92/738f7d23bb2d9642bab520020873cccbef49768d.svg)

Hiperparâmetros
Os hiperparâmetros são várias configurações usadas para controlar o processo de aprendizado. As CNNs usam mais hiperparâmetros do que um perceptron multicamadas (MLP) padrão.
Preenchimento (Padding)
O preenchimento (padding) é a adição de pixels (tipicamente) com valor 0 nas bordas de uma imagem. Isto é feito para que os pixels da borda não sejam subvalorizados (perdidos) na saída, porque normalmente participariam em apenas uma única instância de campo receptivo. O preenchimento aplicado é tipicamente um a menos que a dimensão correspondente do núcleo (kernel). Por exemplo, uma camada convolucional usando núcleos 3x3 receberia um preenchimento de 2 pixels, ou seja, 1 pixel em cada lado da imagem.
Passo (Stride)
O passo (stride) é o número de pixels que a janela de análise se move em cada iteração. Um passo de 2 significa que cada núcleo é deslocado em 2 pixels em relação ao seu antecessor.
Número de filtros
Como o tamanho do mapa de características diminui com a profundidade, as camadas próximas à camada de entrada tendem a ter menos filtros, enquanto as camadas mais altas podem ter mais. Para igualar a computação em cada camada, o produto dos valores das características va com a posição do pixel é mantido aproximadamente constante ao longo das camadas. Preservar mais informações sobre a entrada exigiria manter o número total de ativações (número de mapas de características vezes o número de posições de pixels) não decrescente de uma camada para a seguinte.
O número de mapas de características controla diretamente a capacidade e depende do número de exemplos disponíveis e da complexidade da tarefa.
Tamanho do filtro (ou núcleo)
Os tamanhos de filtro comuns encontrados na literatura variam muito e geralmente são escolhidos com base no conjunto de dados. Os tamanhos típicos de filtro variam de 1x1 a 7x7. Como dois exemplos famosos, a AlexNet usou 3x3, 5x5 e 11x11. A Inceptionv3 usou 1x1, 3x3 e 5x5.
O desafio é encontrar o nível certo de granularidade para criar abstrações na escala adequada, dado um conjunto de dados específico e sem sobreajuste (overfitting).
Tipo e tamanho de pooling
O agrupamento máximo (max pooling) é tipicamente usado, muitas vezes com uma dimensão 2x2. Isto implica que a entrada é drasticamente subamostrada, reduzindo o custo de processamento.
Um agrupamento maior reduz a dimensão do sinal e pode resultar numa perda de informação inaceitável. Freqüentemente, janelas de agrupamento não sobrepostas apresentam o melhor desempenho.
Dilatação
A dilatação envolve ignorar pixels dentro de um núcleo. Isto reduz a memória de processamento potencialmente sem perda significativa de sinal. Uma dilatação de 2 num núcleo 3x3 expande o núcleo para 5x5, enquanto ainda processa 9 pixels (espaçados uniformemente). Especificamente, os pixels processados após a dilatação são as células (1,1), (1,3), (1,5), (3,1), (3,3), (3,5), (5,1), (5,3), (5,5), onde (i,j) denota a célula da i-ésima linha e da j-ésima coluna no núcleo expandido 5x5. Assim, a dilatação de 4 expande o núcleo para 7x7.
Equivariância de translação e aliasing
Geralmente assume-se que as CNNs são invariantes a deslocamentos da entrada. Camadas de convolução ou agrupamento (pooling) dentro de uma CNN que não têm um passo (stride) maior do que um são, de fato, equivariantes a translações da entrada. No entanto, camadas com um passo maior do que um ignoram o teorema da amostragem de Nyquist-Shannon e podem levar ao aliasing (serrilhamento) do sinal de entrada. Embora, em princípio, as CNNs sejam capazes de implementar filtros anti-aliasing, observou-se que isso não acontece na prática,[80] e, portanto, geram modelos que não são equivariantes a translações.
Além disso, se uma CNN fizer uso de camadas totalmente conectadas, a equivariância de translação não implica invariância de translação, uma vez que as camadas totalmente conectadas não são invariantes a deslocamentos da entrada.[81] Uma solução para a invariância de translação completa é evitar qualquer subamostragem (down-sampling) em toda a rede e aplicar um agrupamento médio global (global average pooling) na última camada. Adicionalmente, várias outras soluções parciais foram propostas, como o anti-aliasing antes das operações de subamostragem,[82] redes de transformadores espaciais (spatial transformer networks),[83] aumento de dados (data augmentation), subamostragem combinada com agrupamento, e redes neurais de cápsulas (capsule neural networks).[84]
Métodos de regularização
A regularização é um processo de introdução de informações adicionais para resolver um problema mal colocado ou para evitar o sobreajuste (overfitting). As CNNs usam vários tipos de regularização.
Empíricos
Dropout
Como as redes têm tantos parâmetros, elas são propensas ao sobreajuste. Um método para reduzir o sobreajuste é o dropout, introduzido em 2014.[85] Em cada estágio de treinamento, nós individuais são "descartados" da rede (ignorados) com probabilidade ou mantidos com probabilidade , de modo a restar uma rede reduzida; as arestas de entrada e saída de um nó descartado também são removidas. Apenas a rede reduzida é treinada com os dados nesse estágio. Os nós removidos são depois reinseridos na rede com os seus pesos originais.


Nos estágios de treinamento, é geralmente 0,5; para nós de entrada, é tipicamente muito maior porque a informação é perdida diretamente quando os nós de entrada são ignorados.
No momento do teste, após a conclusão do treinamento, idealmente gostaríamos de encontrar uma média amostral de todas as possíveis redes com dropout; infelizmente, isso é inviável para valores grandes de . No entanto, podemos encontrar uma aproximação usando a rede completa com a saída de cada nó ponderada por um fator de , de modo que o valor esperado da saída de qualquer nó seja o mesmo que nos estágios de treinamento. Esta é a maior contribuição do método dropout: embora ele efetivamente gere redes neurais, permitindo assim a combinação de modelos, no momento do teste apenas uma única rede precisa ser testada.


Ao evitar o treinamento de todos os nós em todos os dados de treinamento, o dropout diminui o sobreajuste. O método também melhora significativamente a velocidade de treinamento. Isso torna a combinação de modelos prática, mesmo para redes neurais profundas. A técnica parece reduzir as interações entre os nós, levando-os a aprender características mais robustas que generalizam melhor para novos dados.
DropConnect
O DropConnect é a generalização do dropout na qual cada conexão, em vez de cada unidade de saída, pode ser descartada com probabilidade . Cada unidade recebe assim entrada de um subconjunto aleatório de unidades na camada anterior.[86]
O DropConnect é semelhante ao dropout, pois introduz esparsidade dinâmica no modelo, mas difere no fato de que a esparsidade recai sobre os pesos, e não sobre os vetores de saída de uma camada. Em outras palavras, a camada totalmente conectada com o DropConnect torna-se uma camada escassamente conectada na qual as conexões são escolhidas aleatoriamente durante o estágio de treinamento.
Agrupamento estocástico (Stochastic pooling)
Uma grande desvantagem do dropout é que ele não tem os mesmos benefícios para as camadas convolucionais, onde os neurônios não estão totalmente conectados.
Mesmo antes do dropout, em 2013, com uma técnica chamada agrupamento estocástico (stochastic pooling),[87] as operações convencionais de agrupamento determinístico foram substituídas por um procedimento estocástico, onde a ativação dentro de cada região de agrupamento é escolhida aleatoriamente de acordo com uma distribuição multinomial, dada pelas atividades dentro da região de agrupamento. Esta abordagem é livre de hiperparâmetros e pode ser combinada com outras abordagens de regularização, como o dropout e o aumento de dados.
Uma visão alternativa do agrupamento estocástico é que ele é equivalente ao agrupamento máximo (max pooling) padrão, mas com muitas cópias de uma imagem de entrada, cada uma com pequenas deformações locais. Isso é semelhante a deformações elásticas explícitas das imagens de entrada,[88] que oferece um excelente desempenho no conjunto de dados MNIST.[88] O uso de agrupamento estocástico num modelo multicamadas fornece um número exponencial de deformações, uma vez que as seleções nas camadas superiores são independentes das que estão abaixo.
Dados artificiais
Como o grau de sobreajuste de um modelo é determinado tanto pelo seu poder como pela quantidade de treinamento que recebe, fornecer a uma rede convolucional mais exemplos de treinamento pode reduzir o sobreajuste. Como muitas vezes não há dados disponíveis suficientes para treinar, especialmente considerando que alguma parte deve ser poupada para testes posteriores, duas abordagens são gerar novos dados do zero (se possível) ou perturbar dados existentes para criar novos. Esta última é utilizada desde meados da década de 1990. Por exemplo, as imagens de entrada podem ser recortadas, giradas ou redimensionadas para criar novos exemplos com os mesmos rótulos do conjunto de treinamento original.[89]
Explícitos
Parada antecipada (Early stopping)
Um dos métodos mais simples para evitar o sobreajuste de uma rede é simplesmente interromper o treinamento antes que o sobreajuste tenha a chance de ocorrer. Isso tem a desvantagem de interromper o processo de aprendizado.
Número de parâmetros
Outra forma simples de evitar o sobreajuste é limitar o número de parâmetros, tipicamente limitando o número de unidades ocultas em cada camada ou limitando a profundidade da rede. Para redes convolucionais, o tamanho do filtro também afeta o número de parâmetros. Limitar o número de parâmetros restringe o poder preditivo da rede diretamente, reduzindo a complexidade da função que ela pode executar nos dados e, assim, limita a quantidade de sobreajuste. Isto é equivalente a uma "norma zero".
Decaimento de pesos (Weight decay)
Uma forma simples de regularizador adicionado é o decaimento de pesos, que simplesmente adiciona um erro extra, proporcional à soma dos pesos (norma L1) ou à magnitude ao quadrado (norma L2) do vetor de pesos, ao erro em cada nó. O nível de complexidade aceitável do modelo pode ser reduzido aumentando a constante de proporcionalidade (hiperparâmetro 'alfa'), aumentando assim a penalização para vetores de peso grandes.
A regularização L2 é a forma mais comum de regularização. Pode ser implementada penalizando a magnitude ao quadrado de todos os parâmetros diretamente no objetivo. A regularização L2 tem a interpretação intuitiva de penalizar fortemente vetores de peso com picos e preferir vetores de peso difusos. Devido às interações multiplicativas entre pesos e entradas, isso tem a propriedade útil de encorajar a rede a usar um pouco todas as suas entradas, em vez de usar muito apenas algumas delas.
A regularização L1 também é comum. Torna os vetores de peso esparsos durante a otimização. Em outras palavras, os neurônios com regularização L1 acabam utilizando apenas um subconjunto esparso das suas entradas mais importantes e tornam-se quase invariantes a entradas ruidosas. A regularização L1 pode ser combinada com a L2; a isto chama-se regularização de rede elástica.
Restrições de norma máxima
Outra forma de regularização é impor um limite superior absoluto na magnitude do vetor de pesos para cada neurônio e usar a descida de gradiente projetada para impor a restrição. Na prática, isso corresponde a realizar a atualização dos parâmetros normalmente e, em seguida, impor a restrição fixando o vetor de pesos de cada neurônio para satisfazer . Valores típicos de são da ordem de 3–4. Alguns artigos relatam melhorias[90] ao usar esta forma de regularização.



Sistemas de coordenadas hierárquicos
O agrupamento (pooling) perde as relações espaciais precisas entre partes de alto nível (como o nariz e a boca numa imagem de rosto). Estas relações são necessárias para o reconhecimento de identidade. A sobreposição das áreas de agrupamento, para que cada característica ocorra em múltiplos agrupamentos, ajuda a reter a informação. A translação por si só não consegue extrapolar a compreensão das relações geométricas para um ponto de vista radicalmente novo, tal como uma orientação ou escala diferente. Por outro lado, as pessoas são muito boas a extrapolar; depois de verem uma nova forma uma vez, conseguem reconhecê-la a partir de um ponto de vista diferente.[91]
Uma forma anterior comum de lidar com este problema é treinar a rede com dados transformados em diferentes orientações, escalas, iluminação, etc., para que a rede possa lidar com estas variações. Isto é computacionalmente intensivo para grandes conjuntos de dados. A alternativa é usar uma hierarquia de sistemas de coordenadas (coordinate frames) e usar um grupo de neurônios para representar uma conjunção da forma da característica e da sua pose em relação à retina. A pose em relação à retina é a relação entre o sistema de coordenadas da retina e o sistema de coordenadas das características intrínsecas.[92]
Assim, uma forma de representar algo é incorporar o sistema de coordenadas dentro dele. Isso permite que características grandes sejam reconhecidas usando a consistência das poses das suas partes (por ex., as poses do nariz e da boca fazem uma previsão consistente da pose de todo o rosto). Esta abordagem garante que a entidade de nível superior (por ex., rosto) está presente quando as entidades de nível inferior (por ex., nariz e boca) concordam na sua previsão da pose. Os vetores de atividade neuronal que representam a pose ("vetores de pose") permitem transformações espaciais modeladas como operações lineares que tornam mais fácil para a rede aprender a hierarquia de entidades visuais e generalizar através de diferentes pontos de vista. Isto é semelhante à forma como o sistema visual humano impõe sistemas de coordenadas para representar formas.[93]
Referências
- ↑ «Convolutional Neural Networks (LeNet) - DeepLearning 0.1 documentation». DeepLearning 0.1. LISA Lab. Consultado em 31 de agosto de 2013
- ↑ Zhang, Wei (1988). «Shift-invariant pattern recognition neural network and its optical architecture». Proceedings of annual conference of the Japan Society of Applied Physics
- ↑ Zhang, Wei (1990). «Parallel distributed processing model with local space-invariant interconnections and its optical architecture». Applied Optics. 29 (32): 4790–7. Bibcode:1990ApOpt..29.4790Z. PMID 20577468. doi:10.1364/AO.29.004790
- ↑ Matusugu, Masakazu; Katsuhiko Mori; Yusuke Mitari; Yuji Kaneda (2003). «Subject independent facial expression recognition with robust face detection using a convolutional neural network» (PDF). Neural Networks. 16 (5): 555–559. doi:10.1016/S0893-6080(03)00115-1. Consultado em 17 de novembro de 2013
- ↑ LeCun, Yann. «LeNet-5, convolutional neural networks». Consultado em 16 de novembro de 2013
- ↑ Gulshan, Varun; Peng, Lily; Coram, Marc; Stumpe, Martin C.; Wu, Derek; Narayanaswamy, Arunachalam; Venugopalan, Subhashini; Widner, Kasumi; Madams, Tom (13 de dezembro de 2016). «Development and Validation of a Deep Learning Algorithm for Detection of Diabetic Retinopathy in Retinal Fundus Photographs». JAMA (em inglês). 316 (22). ISSN 0098-7484. doi:10.1001/jama.2016.17216
- ↑ Esteva, Andre; Kuprel, Brett; Novoa, Roberto A.; Ko, Justin; Swetter, Susan M.; Blau, Helen M.; Thrun, Sebastian (fevereiro de 2017). «Dermatologist-level classification of skin cancer with deep neural networks». Nature (em inglês). 542 (7639): 115–118. ISSN 1476-4687. doi:10.1038/nature21056
- ↑ Convolutional Neural Networks Demystified: A Matched Filtering Perspective Based Tutorial https://arxiv.org/abs/2108.11663v3
- ↑ «Convolutional Neural Networks (LeNet) – DeepLearning 0.1 documentation». DeepLearning 0.1. LISA Lab. Consultado em 31 de agosto de 2013. Cópia arquivada em 28 de dezembro de 2017
- ↑ Chollet, François (4 de abril de 2017). «Xception: Deep Learning with Depthwise Separable Convolutions». arXiv:1610.02357
 [cs.CV]
[cs.CV] - ↑ Krizhevsky, Alex. «ImageNet Classification with Deep Convolutional Neural Networks» (PDF). Consultado em 17 de novembro de 2013. Cópia arquivada (PDF) em 25 de abril de 2021
- ↑ Yamaguchi, Kouichi; Sakamoto, Kenji; Akabane, Toshio; Fujimoto, Yoshiji (Novembro de 1990). A Neural Network for Speaker-Independent Isolated Word Recognition. First International Conference on Spoken Language Processing (ICSLP 90). Kobe, Japão. Consultado em 4 de setembro de 2019. Cópia arquivada em 7 de março de 2021
- ↑ Ciresan, Dan; Meier, Ueli; Schmidhuber, Jürgen (Junho de 2012). «Multi-column deep neural networks for image classification». 2012 IEEE Conference on Computer Vision and Pattern Recognition. New York, NY: Institute of Electrical and Electronics Engineers (IEEE). pp. 3642–3649. CiteSeerX 10.1.1.300.3283. ISBN 978-1-4673-1226-4. OCLC 812295155. arXiv:1202.2745. doi:10.1109/CVPR.2012.6248110
- ↑ Yu, Fisher; Koltun, Vladlen (30 de abril de 2016). «Multi-Scale Context Aggregation by Dilated Convolutions». arXiv:1511.07122 [cs.CV]
- ↑ Chen, Liang-Chieh; Papandreou, George; Schroff, Florian; Adam, Hartwig (5 de dezembro de 2017). «Rethinking Atrous Convolution for Semantic Image Segmentation». arXiv:1706.05587 [cs.CV]
- ↑ Duta, Ionut Cosmin; Georgescu, Mariana Iuliana; Ionescu, Radu Tudor (16 de agosto de 2021). «Contextual Convolutional Neural Networks». arXiv:2108.07387 [cs.CV]
- ↑ LeCun, Yann. «LeNet-5, convolutional neural networks». Consultado em 16 de novembro de 2013. Cópia arquivada em 24 de fevereiro de 2021
- ↑ Zeiler, Matthew D.; Taylor, Graham W.; Fergus, Rob (Novembro de 2011). «Adaptive deconvolutional networks for mid and high level feature learning». 2011 International Conference on Computer Vision. [S.l.]: IEEE. pp. 2018–2025. ISBN 978-1-4577-1102-2. doi:10.1109/iccv.2011.6126474 Parâmetro desconhecido
|capitulo-url=ignorado (ajuda) - ↑ Dumoulin, Vincent; Visin, Francesco (11 de janeiro de 2018). «A guide to convolution arithmetic for deep learning». arXiv:1603.07285
- ↑ Odena, Augustus; Dumoulin, Vincent; Olah, Chris (17 de outubro de 2016). «Deconvolution and Checkerboard Artifacts». Distill (em inglês). 1 (10). ISSN 2476-0757. doi:10.23915/distill.00003 Parâmetro desconhecido
|numero-artigo=ignorado (ajuda) - ↑ van Dyck, Leonard Elia; Kwitt, Roland; Denzler, Sebastian Jochen; Gruber, Walter Roland (2021). «Comparing Object Recognition in Humans and Deep Convolutional Neural Networks—An Eye Tracking Study». Frontiers in Neuroscience. 15. ISSN 1662-453X. PMC 8526843. PMID 34690686. doi:10.3389/fnins.2021.750639 Parâmetro desconhecido
|numero-artigo=ignorado (ajuda) - 1 2 Hubel, DH; Wiesel, TN (Outubro de 1959). «Receptive fields of single neurones in the cat's striate cortex». J. Physiol. 148 (3): 574–91. PMC 1363130. PMID 14403679. doi:10.1113/jphysiol.1959.sp006308
- ↑ Hubel, D. H.; Wiesel, T. N. (1 de março de 1968). «Receptive fields and functional architecture of monkey striate cortex». The Journal of Physiology. 195 (1): 215–243. ISSN 0022-3751. PMC 1557912. PMID 4966457. doi:10.1113/jphysiol.1968.sp008455
- ↑ David H. Hubel and Torsten N. Wiesel (2005). Brain and visual perception: the story of a 25-year collaboration. [S.l.]: Oxford University Press US. p. 106. ISBN 978-0-19-517618-6. Consultado em 18 de janeiro de 2019. Cópia arquivada em 16 de outubro de 2023
- ↑ Fukushima, K. (1969). «Visual feature extraction by a multilayered network of analog threshold elements». IEEE Transactions on Systems Science and Cybernetics. 5 (4): 322–333. Bibcode:1969ITSSC...5..322F. doi:10.1109/TSSC.1969.300225
- ↑ Schmidhuber, Juergen (2022). «Annotated History of Modern AI and Deep Learning». arXiv:2212.11279 [cs.NE] Parâmetro desconhecido
|link-autor=ignorado (ajuda) - ↑ Fukushima, Kunihiko (1980). «Neocognitron: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position» (PDF). Biological Cybernetics. 36 (4): 193–202. PMID 7370364. doi:10.1007/BF00344251. Consultado em 16 de novembro de 2013. Cópia arquivada (PDF) em 3 de junho de 2014
- ↑ Ramachandran, Prajit; Barret, Zoph; Quoc, V. Le (16 de outubro de 2017). «Searching for Activation Functions». arXiv:1710.05941 [cs.NE]
- 1 2 Homma, Toshiteru; Les Atlas; Robert Marks II (1987). «An Artificial Neural Network for Spatio-Temporal Bipolar Patterns: Application to Phoneme Classification» (PDF). Advances in Neural Information Processing Systems. 1: 31–40. Consultado em 31 de março de 2022. Cópia arquivada (PDF) em 31 de março de 2022.
A noção de convolução ou correlação usada nos modelos apresentados é popular nas disciplinas de engenharia e tem sido aplicada extensivamente no design de filtros, sistemas de controle, etc.
- 1 2 Waibel, Alex (18 de dezembro de 1987). Phoneme Recognition Using Time-Delay Neural Networks (PDF). Meeting of the Institute of Electrical, Information and Communication Engineers (IEICE). Tóquio, Japão
- ↑ Alexander Waibel et al., Phoneme Recognition Using Time-Delay Neural Networks Arquivado em 2021-02-25 no Wayback Machine IEEE Transactions on Acoustics, Speech, and Signal Processing, Volume 37, No. 3, pp. 328. - 339 Março de 1989.
- ↑ LeCun, Yann; Bengio, Yoshua (1995). «Convolutional networks for images, speech, and time series». The handbook of brain theory and neural networks Second ed. The MIT press. pp. 276–278. Consultado em 3 de dezembro de 2019. Cópia arquivada em 28 de julho de 2020 Parâmetro desconhecido
|editor-primeiro=ignorado (ajuda); Parâmetro desconhecido|editor-ultimo=ignorado (ajuda);|nome1=sem|sobrenome1=em Editors list (ajuda) - ↑ John B. Hampshire and Alexander Waibel, Connectionist Architectures for Multi-Speaker Phoneme Recognition Arquivado em 2022-03-31 no Wayback Machine, Advances in Neural Information Processing Systems, 1990, Morgan Kaufmann.
- ↑ Ko, Tom; Peddinti, Vijayaditya; Povey, Daniel; Seltzer, Michael L.; Khudanpur, Sanjeev (Março de 2018). A Study on Data Augmentation of Reverberant Speech for Robust Speech Recognition (PDF). The 42nd IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP 2017). New Orleans, LA, EUA. Consultado em 4 de setembro de 2019. Cópia arquivada (PDF) em 8 de julho de 2018
- ↑ Denker, J S, Gardner, W R, Graf, H. P, Henderson, D, Howard, R E, Hubbard, W, Jackel, L D, BaIrd, H S, and Guyon (1989) Neural network recognizer for hand-written zip code digits Arquivado em 2018-08-04 no Wayback Machine, AT&T Bell Laboratories
- 1 2 Y. LeCun, B. Boser, J. S. Denker, D. Henderson, R. E. Howard, W. Hubbard, L. D. Jackel, Backpropagation Applied to Handwritten Zip Code Recognition Arquivado em 2020-01-10 no Wayback Machine; AT&T Bell Laboratories
- 1 2 Zhang, Wei (1991). «Image processing of human corneal endothelium based on a learning network». Applied Optics. 30 (29): 4211–7. Bibcode:1991ApOpt..30.4211Z. PMID 20706526. doi:10.1364/AO.30.004211. Consultado em 22 de setembro de 2016. Cópia arquivada em 6 de fevereiro de 2017
- 1 2 Zhang, Wei (1994). «Computerized detection of clustered microcalcifications in digital mammograms using a shift-invariant artificial neural network». Medical Physics. 21 (4): 517–24. Bibcode:1994MedPh..21..517Z. PMID 8058017. doi:10.1118/1.597177. Consultado em 22 de setembro de 2016. Cópia arquivada em 6 de fevereiro de 2017
- ↑ Weng, J; Ahuja, N; Huang, TS (1993). «Learning recognition and segmentation of 3-D objects from 2-D images». 1993 (4th) International Conference on Computer Vision. [S.l.]: IEEE. pp. 121–128. ISBN 0-8186-3870-2. doi:10.1109/ICCV.1993.378228
- 1 2 Schmidhuber, Jürgen (2015). «Deep Learning». Scholarpedia. 10 (11): 1527–54. CiteSeerX 10.1.1.76.1541. PMID 16764513. doi:10.1162/neco.2006.18.7.1527. Consultado em 20 de janeiro de 2019. Cópia arquivada em 19 de abril de 2016
- ↑ Lecun, Y.; Jackel, L. D.; Bottou, L.; Cortes, C.; Denker, J. S.; Drucker, H.; Guyon, I.; Muller, U. A.; Sackinger, E.; Simard, P.; Vapnik, V. (Agosto de 1995). Learning algorithms for classification: A comparison on handwritten digit recognition (PDF). [S.l.]: World Scientific. pp. 261–276. ISBN 978-981-02-2324-3. doi:10.1142/2808. Cópia arquivada (PDF) em 2 de maio de 2023
- ↑ Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. (Novembro de 1998). «Gradient-based learning applied to document recognition». Proceedings of the IEEE. 86 (11): 2278–2324. Bibcode:1998IEEEP..86.2278L. doi:10.1109/5.726791
- ↑ Zhang, Wei (1991). «Error Back Propagation with Minimum-Entropy Weights: A Technique for Better Generalization of 2-D Shift-Invariant NNs». Proceedings of the International Joint Conference on Neural Networks. Consultado em 22 de setembro de 2016. Cópia arquivada em 6 de fevereiro de 2017
- ↑ Daniel Graupe, Ruey Wen Liu, George S Moschytz."Applications of neural networks to medical signal processing Arquivado em 2020-07-28 no Wayback Machine". In Proc. 27th IEEE Decision and Control Conf., pp. 343–347, 1988.
- ↑ Daniel Graupe, Boris Vern, G. Gruener, Aaron Field, and Qiu Huang. "Decomposition of surface EMG signals into single fiber action potentials by means of neural network Arquivado em 2019-09-04 no Wayback Machine". Proc. IEEE International Symp. on Circuits and Systems, pp. 1008–1011, 1989.
- ↑ Qiu Huang, Daniel Graupe, Yi Fang Huang, Ruey Wen Liu."Identification of firing patterns of neuronal signals[ligação inativa]." In Proc. 28th IEEE Decision and Control Conf., pp. 266–271, 1989. https://ieeexplore.ieee.org/document/70115 Arquivado em 2022-03-31 no Wayback Machine
- ↑ Oh, KS; Jung, K (2004). «GPU implementation of neural networks.». Pattern Recognition. 37 (6): 1311–1314. Bibcode:2004PatRe..37.1311O. doi:10.1016/j.patcog.2004.01.013
- ↑ Dave Steinkraus; Patrice Simard; Ian Buck (2005). «Using GPUs for Machine Learning Algorithms». 12th International Conference on Document Analysis and Recognition (ICDAR 2005). pp. 1115–1119. doi:10.1109/ICDAR.2005.251. Cópia arquivada em 31 de março de 2022
|arquivourl=requer|url=(ajuda) Parâmetro desconhecido|capitulo-url=ignorado (ajuda); - ↑ Kumar Chellapilla; Sid Puri; Patrice Simard (2006). Guy Lorette, ed. High Performance Convolutional Neural Networks for Document Processing. Tenth International Workshop on Frontiers in Handwriting Recognition. Suvisoft. Consultado em 14 de março de 2016. Cópia arquivada em 18 de maio de 2020
- ↑ Hinton, GE; Osindero, S; Teh, YW (Julho de 2006). «A fast learning algorithm for deep belief nets.». Neural Computation. 18 (7): 1527–54. CiteSeerX 10.1.1.76.1541. PMID 16764513. doi:10.1162/neco.2006.18.7.1527
- ↑ Bengio, Yoshua; Lamblin, Pascal; Popovici, Dan; Larochelle, Hugo (2007). «Greedy Layer-Wise Training of Deep Networks» (PDF). Advances in Neural Information Processing Systems: 153–160. Consultado em 31 de março de 2022. Cópia arquivada (PDF) em 2 de junho de 2022
- ↑ Ranzato, MarcAurelio; Poultney, Christopher; Chopra, Sumit; LeCun, Yann (2007). «Efficient Learning of Sparse Representations with an Energy-Based Model» (PDF). Advances in Neural Information Processing Systems. Consultado em 26 de junho de 2014. Cópia arquivada (PDF) em 22 de março de 2016
- ↑ Raina, R; Madhavan, A; Ng, Andrew (14 de junho de 2009). «Large-scale deep unsupervised learning using graphics processors». Proceedings of the 26th Annual International Conference on Machine Learning. [S.l.]: ICML '09: Proceedings of the 26th Annual International Conference on Machine Learning. pp. 873–880. ISBN 978-1-60558-516-1. doi:10.1145/1553374.1553486. Cópia arquivada (PDF) em 8 de dezembro de 2020
|arquivourl=requer|url=(ajuda) Parâmetro desconhecido|capitulo-url=ignorado (ajuda); - ↑ Ciresan, Dan; Meier, Ueli; Gambardella, Luca; Schmidhuber, Jürgen (2010). «Deep big simple neural nets for handwritten digit recognition.». Neural Computation. 22 (12): 3207–3220. Bibcode:2010NeCom..22.3207C. PMID 20858131. arXiv:1003.0358. doi:10.1162/NECO_a_00052
- ↑ Ciresan, Dan; Ueli Meier; Jonathan Masci; Luca M. Gambardella; Jurgen Schmidhuber (2011). «Flexible, High Performance Convolutional Neural Networks for Image Classification» (PDF). Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence-Volume Volume Two. 2: 1237–1242. Consultado em 17 de novembro de 2013. Cópia arquivada (PDF) em 5 de abril de 2022
- ↑ «IJCNN 2011 Competition result table». OFFICIAL IJCNN2011 COMPETITION (em inglês). 2010. Consultado em 14 de janeiro de 2019. Cópia arquivada em 17 de janeiro de 2021
- ↑ Schmidhuber, Jürgen (17 de março de 2017). «History of computer vision contests won by deep CNNs on GPU» (em inglês). Consultado em 14 de janeiro de 2019. Cópia arquivada em 19 de dezembro de 2018
- ↑ Viebke, Andre; Memeti, Suejb; Pllana, Sabri; Abraham, Ajith (2019). «CHAOS: a parallelization scheme for training convolutional neural networks on Intel Xeon Phi». The Journal of Supercomputing. 75 (1): 197–227. arXiv:1702.07908. doi:10.1007/s11227-017-1994-x
- ↑ Viebke, Andre; Pllana, Sabri (2015). «The Potential of the Intel (R) Xeon Phi for Supervised Deep Learning». 2015 IEEE 17th International Conference on High Performance Computing and Communications, 2015 IEEE 7th International Symposium on Cyberspace Safety and Security, and 2015 IEEE 12th International Conference on Embedded Software and Systems. IEEE Xplore. IEEE 2015. pp. 758–765. ISBN 978-1-4799-8937-9. doi:10.1109/HPCC-CSS-ICESS.2015.45. Cópia arquivada em 6 de março de 2023
|arquivourl=requer|url=(ajuda) Parâmetro desconhecido|capitulo-url=ignorado (ajuda); - ↑ Hinton, Geoffrey (2012). «ImageNet Classification with Deep Convolutional Neural Networks». NIPS'12: Proceedings of the 25th International Conference on Neural Information Processing Systems - Volume 1. 1: 1097–1105. Consultado em 26 de março de 2021. Cópia arquivada em 20 de dezembro de 2019 – via ACM
- 1 2 Géron, Aurélien (2019). Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow. Sebastopol, CA: O'Reilly Media. ISBN 978-1-492-03264-9, pp. 448
- ↑ Quando aplicado a outros tipos de dados além de dados de imagem, como dados de som, a "posição espacial" pode corresponder variavelmente a diferentes pontos no domínio do tempo, no domínio da frequência ou noutros espaços matemáticos.
- ↑ Li, Zewen; Liu, Fan; Yang, Wenjie; Peng, Shouheng; Zhou, Jun (Dezembro de 2022). «A Survey of Convolutional Neural Networks: Analysis, Applications, and Prospects». IEEE Transactions on Neural Networks and Learning Systems. 33 (12): 6999–7019. Bibcode:2022ITNNL..33.6999L. PMID 34111009. arXiv:2004.02806. doi:10.1109/TNNLS.2021.3084827. hdl:10072/405164
- ↑ «CS231n Convolutional Neural Networks for Visual Recognition». cs231n.github.io. Consultado em 25 de abril de 2017. Cópia arquivada em 23 de outubro de 2019
- ↑ daí o nome "camada convolucional"
- ↑ Nirthika, Rajendran; Manivannan, Siyamalan; Ramanan, Amirthalingam; Wang, Ruixuan (1 de abril de 2022). «Pooling in convolutional neural networks for medical image analysis: a survey and an empirical study». Neural Computing and Applications (em inglês). 34 (7): 5321–5347. ISSN 1433-3058. PMC 8804673. PMID 35125669. doi:10.1007/s00521-022-06953-8
- ↑ Azulay, Aharon; Weiss, Yair (2019). «Why do deep convolutional networks generalize so poorly to small image transformations?». Journal of Machine Learning Research. 20 (184): 1–25. ISSN 1533-7928. Consultado em 31 de março de 2022. Cópia arquivada em 31 de março de 2022
- ↑ Scherer, Dominik; Müller, Andreas C.; Behnke, Sven (2010). «Evaluation of Pooling Operations in Convolutional Architectures for Object Recognition» (PDF). Artificial Neural Networks (ICANN), 20th International Conference on. Salónica, Grécia: Springer. pp. 92–101. Consultado em 28 de dezembro de 2016. Cópia arquivada (PDF) em 3 de abril de 2018
- ↑ Graham, Benjamin (18 de dezembro de 2014). «Fractional Max-Pooling». arXiv:1412.6071 [cs.CV]
- ↑ Springenberg, Jost Tobias; Dosovitskiy, Alexey; Brox, Thomas; Riedmiller, Martin (21 de dezembro de 2014). «Striving for Simplicity: The All Convolutional Net». arXiv:1412.6806 [cs.LG]
- ↑ Ma, Zhanyu; Chang, Dongliang; Xie, Jiyang; Ding, Yifeng; Wen, Shaoguo; Li, Xiaoxu; Si, Zhongwei; Guo, Jun (2019). «Fine-Grained Vehicle Classification With Channel Max Pooling Modified CNNs». Institute of Electrical and Electronics Engineers (IEEE). IEEE Transactions on Vehicular Technology. 68 (4): 3224–3233. Bibcode:2019ITVT...68.3224M. ISSN 0018-9545. doi:10.1109/tvt.2019.2899972
- ↑ Zafar, Afia; Aamir, Muhammad; Mohd Nawi, Nazri; Arshad, Ali; Riaz, Saman; Alruban, Abdulrahman; Dutta, Ashit Kumar; Almotairi, Sultan (29 de agosto de 2022). «A Comparison of Pooling Methods for Convolutional Neural Networks». Applied Sciences (em inglês). 12 (17): 8643. Bibcode:2022ApSci..12.8643Z. ISSN 2076-3417. doi:10.3390/app12178643
- ↑ Gholamalinezhad, Hossein; Khosravi, Hossein (16 de setembro de 2020). «Pooling Methods in Deep Neural Networks, a Review». arXiv:2009.07485
- ↑ Householder, Alston S. (Junho de 1941). «A theory of steady-state activity in nerve-fiber networks: I. Definitions and preliminary lemmas». The Bulletin of Mathematical Biophysics (em inglês). 3 (2): 63–69. ISSN 0007-4985. doi:10.1007/BF02478220
- ↑ Krizhevsky, Alex; Sutskever, Ilya; Hinton, Geoffrey E. (24 de maio de 2017). «ImageNet classification with deep convolutional neural networks» (PDF). Communications of the ACM. 60 (6): 84–90. ISSN 0001-0782. doi:10.1145/3065386. Consultado em 4 de dezembro de 2018. Cópia arquivada (PDF) em 16 de maio de 2017
- ↑ Romanuke, Vadim (2017). «Appropriate number and allocation of ReLUs in convolutional neural networks». Research Bulletin of NTUU "Kyiv Polytechnic Institute". 1 (1): 69–78. doi:10.20535/1810-0546.2017.1.88156
- ↑ Xavier Glorot; Antoine Bordes; Yoshua Bengio (2011). Deep sparse rectifier neural networks (PDF). AISTATS. Consultado em 10 de abril de 2023. Cópia arquivada (PDF) em 13 de dezembro de 2016.
Rectifier and softplus activation functions. The second one is a smooth version of the first.
- ↑ Krizhevsky, A.; Sutskever, I.; Hinton, G. E. (2012). «Imagenet classification with deep convolutional neural networks» (PDF). Advances in Neural Information Processing Systems. 1: 1097–1105. Consultado em 31 de março de 2022. Cópia arquivada (PDF) em 31 de março de 2022
- ↑ Os chamados dados categóricos.
- ↑ Ribeiro, Antonio H.; Schön, Thomas B. (2021). «How Convolutional Neural Networks Deal with Aliasing». ICASSP 2021 - 2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). [S.l.: s.n.] pp. 2755–2759. ISBN 978-1-7281-7605-5. arXiv:2102.07757. doi:10.1109/ICASSP39728.2021.9414627
- ↑ Johannes C. Myburgh; Coenraad Mouton; Marelie H. Davel (2020). «Tracking Translation Invariance in CNNs». In: Aurona Gerber. Artificial Intelligence Research. Col: Communications in Computer and Information Science (em inglês). 1342. Cham: Springer International Publishing. pp. 282–295. ISBN 978-3-030-66151-9. arXiv:2104.05997. doi:10.1007/978-3-030-66151-9_18. Consultado em 26 de março de 2021. Cópia arquivada em 22 de janeiro de 2022
- ↑ Richard, Zhang (25 de abril de 2019). Making Convolutional Networks Shift-Invariant Again. [S.l.: s.n.] OCLC 1106340711
- ↑ Jadeberg, Max; Simonyan, Karen; Zisserman, Andrew; Kavukcuoglu, Koray (2015). «Spatial Transformer Networks» (PDF). Advances in Neural Information Processing Systems. 28. Consultado em 26 de março de 2021. Cópia arquivada (PDF) em 25 de julho de 2021 – via NIPS
- ↑ Sabour, Sara; Frosst, Nicholas; Hinton, Geoffrey E. (26 de outubro de 2017). Dynamic Routing Between Capsules. [S.l.: s.n.] OCLC 1106278545
- ↑ Srivastava, Nitish; C. Geoffrey Hinton; Alex Krizhevsky; Ilya Sutskever; Ruslan Salakhutdinov (2014). «Dropout: A Simple Way to Prevent Neural Networks from overfitting» (PDF). Journal of Machine Learning Research. 15 (1): 1929–1958. Consultado em 3 de janeiro de 2015. Cópia arquivada (PDF) em 19 de janeiro de 2016
- ↑ «Regularization of Neural Networks using DropConnect | ICML 2013 | JMLR W&CP». jmlr.org: 1058–1066. 13 de fevereiro de 2013. Consultado em 17 de dezembro de 2015. Cópia arquivada em 12 de agosto de 2017
- ↑ Zeiler, Matthew D.; Fergus, Rob (15 de janeiro de 2013). «Stochastic Pooling for Regularization of Deep Convolutional Neural Networks». arXiv:1301.3557 [cs.LG]
- 1 2 Platt, John; Steinkraus, Dave; Simard, Patrice Y. (Agosto de 2003). «Best Practices for Convolutional Neural Networks Applied to Visual Document Analysis – Microsoft Research». Microsoft Research. Consultado em 17 de dezembro de 2015. Cópia arquivada em 7 de novembro de 2017
- ↑ Hinton, Geoffrey E.; Srivastava, Nitish; Krizhevsky, Alex; Sutskever, Ilya; Salakhutdinov, Ruslan R. (2012). «Improving neural networks by preventing co-adaptation of feature detectors». arXiv:1207.0580 [cs.NE]
- ↑ «Dropout: A Simple Way to Prevent Neural Networks from Overfitting». jmlr.org. Consultado em 17 de dezembro de 2015. Cópia arquivada em 5 de março de 2016
- ↑ Hinton, Geoffrey (1979). «Some demonstrations of the effects of structural descriptions in mental imagery». Cognitive Science. 3 (3): 231–250. doi:10.1016/s0364-0213(79)80008-7
- ↑ Rock, Irvin. "The frame of reference." The legacy of Solomon Asch: Essays in cognition and social psychology (1990): 243–268.
- ↑ J. Hinton, Coursera lectures on Neural Networks, 2012, Url: https://www.coursera.org/learn/neural-networks Arquivado em 2016-12-31 no Wayback Machine