Modelo de difusão
| Parte de uma série sobre |
| Aprendizado de máquina e mineração de dados |
|---|
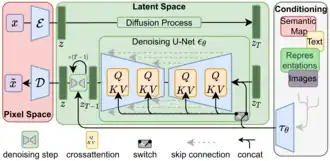

Em aprendizado de máquina, modelos de difusão, também conhecidos como modelos generativos baseados em difusão ou modelos generativos baseados em pontuação, são uma classe de modelos generativos de variáveis latentes. Um modelo de difusão consiste em dois componentes principais: o processo de difusão direta e o processo de amostragem reversa. O objetivo dos modelos de difusão é aprender um processo de difusão para um determinado conjunto de dados, de modo que o processo possa gerar novos elementos que sejam distribuídos de forma semelhante ao conjunto de dados original. Um modelo de difusão modela dados conforme gerados por um processo de difusão, por meio do qual um novo dado executa uma caminhada aleatória com deriva pelo espaço de todos os dados possíveis. [1] Um modelo de difusão treinado pode ser amostrado de muitas maneiras, com eficiência e qualidade diferentes.
Existem vários formalismos equivalentes, incluindo cadeias de Markov, modelos probabilísticos de difusão de redução de ruído, redes de pontuação condicionadas por ruído e equações diferenciais estocásticas. [2] Eles são normalmente treinados usando inferência variacional. [3] O modelo responsável pela redução de ruído é normalmente chamado de "backbone". O backbone pode ser de qualquer tipo, mas normalmente são U-nets ou transformadores.
Desde 2024, os modelos de difusão são usados principalmente para tarefas de visão computacional, incluindo remoção de ruído de imagens, preenchimento de lacunas, super-resolução, geração de imagens e geração de vídeos. Esses modelos geralmente envolvem o treinamento de uma rede neural para remover sequencialmente o ruído de imagens borradas com ruído gaussiano.[1][2] O modelo é treinado para reverter o processo de adição de ruído a uma imagem. Após o treinamento até a convergência, ele pode ser usado para geração de imagens, começando com uma imagem composta de ruído aleatório e aplicando a rede iterativamente para remover o ruído da imagem.
Os geradores de imagens baseados em difusão têm visto amplo interesse comercial, como Stable Diffusion e DALL-E . Esses modelos normalmente combinam modelos de difusão com outros modelos, como codificadores de texto e módulos de atenção cruzada para permitir a geração condicionada por texto. [4]
Além da visão computacional, os modelos de difusão também encontraram aplicações no processamento de linguagem natural [5] como geração de texto [6] e sumarização, [7] geração de som, [8] e aprendizagem por reforçoooooo. [9] [10]
Veja também
- Cadeia de Markov
- Autocodificador variacional
Referências
- ↑ a b Song, Yang; Sohl-Dickstein, Jascha (10 de fevereiro de 2021). «Score-Based Generative Modeling through Stochastic Differential Equations». arXiv:2011.13456
 [cs.LG]
[cs.LG]
- ↑ a b Croitoru, Florinel-Alin; Hondru, Vlad; Ionescu, Radu Tudor; Shah, Mubarak (2023). «Diffusion Models in Vision: A Survey». IEEE Transactions on Pattern Analysis and Machine Intelligence. 45 (9): 10850–10869. Bibcode:2023ITPAM..4510850C. PMID 37030794. arXiv:2209.04747. doi:10.1109/TPAMI.2023.3261988
- ↑ Ho, Jonathan; Jain, Ajay; Abbeel, Pieter (2020). «Denoising Diffusion Probabilistic Models». Curran Associates, Inc. Advances in Neural Information Processing Systems. 33: 6840–6851
- ↑ GLIDE, OpenAI, 22 de setembro de 2023, consultado em 24 de setembro de 2023
- ↑ Li, Yifan; Zhou, Kun; Zhao, Wayne Xin; Wen, Ji-Rong (agosto de 2023). «Diffusion Models for Non-autoregressive Text Generation: A Survey». Proceedings of the Thirty-Second International Joint Conference on Artificial Intelligence. California: International Joint Conferences on Artificial Intelligence Organization. pp. 6692–6701. ISBN 978-1-956792-03-4. arXiv:2303.06574. doi:10.24963/ijcai.2023/750
- ↑ Xu, Weijie; Hu, Wenxiang; Wu, Fanyou; Sengamedu, Srinivasan (2023). «DeTiME: Diffusion-Enhanced Topic Modeling using Encoder-decoder based LLM». Stroudsburg, PA, USA: Association for Computational Linguistics. Findings of the Association for Computational Linguistics: EMNLP 2023: 9040–9057. arXiv:2310.15296. doi:10.18653/v1/2023.findings-emnlp.606
- ↑ Zhang, Haopeng; Liu, Xiao; Zhang, Jiawei (2023). «DiffuSum: Generation Enhanced Extractive Summarization with Diffusion». Stroudsburg, PA, USA: Association for Computational Linguistics. Findings of the Association for Computational Linguistics: ACL 2023: 13089–13100. arXiv:2305.01735. doi:10.18653/v1/2023.findings-acl.828
- ↑ Yang, Dongchao; Yu, Jianwei; Wang, Helin; Wang, Wen; Weng, Chao; Zou, Yuexian; Yu, Dong (2023). «Diffsound: Discrete Diffusion Model for Text-to-Sound Generation». IEEE/ACM Transactions on Audio, Speech, and Language Processing. 31: 1720–1733. Bibcode:2023ITASL..31.1720Y. ISSN 2329-9290. arXiv:2207.09983. doi:10.1109/taslp.2023.3268730
- ↑ Janner, Michael; Du, Yilun (20 de dezembro de 2022). «Planning with Diffusion for Flexible Behavior Synthesis». arXiv:2205.09991 [cs.LG]
- ↑ Chi, Cheng; Xu, Zhenjia (14 de março de 2024). «Diffusion Policy: Visuomotor Policy Learning via Action Diffusion». arXiv:2303.04137 [cs.RO]