Execução (computação)
| Execução de Programa |
|---|
| Conceitos gerais |
|
| Tipos de código |
|
| Estratégia de compilação |
|
| Runtimes notáveis |
|
| Compiladores notáveis e toolchain |
|
Na computação, a execução é o processo pelo qual um programa de computador é processado para realizar as ações que ele codifica. À medida que o processador segue as instruções do programa, efeitos são produzidos de acordo com a semântica dessas instruções. O termo rodar (do inglês, run) é geralmente sinônimo. O ato de iniciar a execução é frequentemente chamado de lançar ou invocar, além de executar e rodar.
Um processador de execução assume muitas formas. Um programa em código de máquina pode ser executado através da interface programável de um computador ou máquina virtual, onde a execução envolve seguir repetidamente um ciclo de busca-decodificação-execução para cada instrução do programa executada pela unidade de controle. O código-fonte pode ser executado por um software interpretador. Um programa pode ser executado em um processo em lote (batch) sem interação humana, ou um usuário pode digitar comandos em uma sessão interativa.
Independência de plataforma
Frequentemente, o software depende de serviços externos, como um ambiente de tempo de execução e uma biblioteca de tempo de execução [en] adaptada ao ambiente hospedeiro para fornecer serviços que podem desacoplar um executável da manipulação direta do computador e de seus periféricos e, assim, fornecer uma solução mais independente de plataforma.
Erro de tempo de execução
Um erro de tempo de execução [en] é detectado após ou durante a execução (estado "rodando") de um programa, enquanto um erro de tempo de compilação é detectado pelo compilador antes de o programa ser executado. A verificação de tipos, alocação de registradores [en], geração de código [en] e otimização de código são normalmente feitas em tempo de compilação, mas podem ser feitas em tempo de execução dependendo da linguagem e do compilador específicos. Muitos outros erros de tempo de execução existem e são tratados de forma diferente por diferentes linguagens de programação, como erros de divisão por zero, erros de domínio, erros de verificação de limites [en] (índice de array fora dos limites), erros de underflow aritmético [en], vários tipos de underflow e erros de estouro (overflow [en]), e muitos outros erros de tempo de execução geralmente considerados como bugs de software, que podem ou não ser capturados e tratados por qualquer linguagem de computador específica.
O tratamento de exceção suporta o tratamento de erros de tempo de execução, fornecendo uma maneira estruturada de capturar situações inesperadas, bem como erros previsíveis ou resultados incomuns, sem a quantidade de verificação de erros "inline" (na linha) exigida por linguagens sem esse recurso. Avanços mais recentes em motores de tempo de execução (runtime engines) permitem o tratamento automatizado de exceções [en], que fornece informações de depuração de "causa raiz" para cada exceção de interesse e é implementado independentemente do código-fonte, anexando um produto de software especial ao motor de tempo de execução.
Depuração
Algumas depurações só podem ser realizadas (ou são mais eficientes ou precisas quando realizadas) em tempo de execução. Erros lógicos [en] e verificação de limites de arrays são exemplos. Por esse motivo, alguns bugs de programação não são descobertos até que o programa seja testado em um ambiente de produção com dados reais, apesar da verificação sofisticada em tempo de compilação e testes de pré-lançamento. Nesse caso, o usuário final pode encontrar uma mensagem de "erro de tempo de execução".
Interpretador
Um sistema que executa diretamente um programa é um interpretador. Normalmente, interpretador refere-se a software, mas uma CPU também é um interpretador; um interpretador implementado em hardware.
Máquina virtual
Uma máquina virtual (VM) é a virtualização/emulação de um sistema de computador. As máquinas virtuais são baseadas em arquiteturas de computador e fornecem a funcionalidade de um computador físico. Suas implementações podem envolver hardware especializado, software ou uma combinação.
As máquinas virtuais diferem e são organizadas por sua função, mostrada aqui:
- Máquinas virtuais de sistema [en] (também denominadas VMs de virtualização completa [en]) fornecem um substituto para uma máquina real. Elas fornecem a funcionalidade necessária para executar sistemas operacionais inteiros. Um hipervisor usa execução nativa para compartilhar e gerenciar hardware, permitindo vários ambientes isolados uns dos outros, mas existindo na mesma máquina física. Hipervisores modernos usam virtualização assistida por hardware [en], hardware específico para virtualização, principalmente das CPUs hospedeiras.
- Máquinas virtuais de processo são projetadas para executar programas de computador em um ambiente independente de plataforma.
Alguns emuladores de máquina virtual, como o QEMU e emuladores de console de videogame, são projetados para também emular (ou "imitar virtualmente") diferentes arquiteturas de sistema, permitindo assim a execução de aplicativos de software e sistemas operacionais escritos para outra CPU ou arquitetura. A virtualização em nível de sistema operacional permite que os recursos de um computador sejam particionados através do kernel. Os termos não são universalmente intercambiáveis.
Nativa do host
Esta seção foca na execução nativa do host (host-native) de um programa escrito em uma linguagem de programação diferente de assembly; interpretação pela CPU de código de máquina gerado a partir do código-fonte. Embora este seja um cenário muito comum para execução, outras formas de execução são comumente encontradas.
Troca de contexto
Para suportar a execução concorrente de vários executáveis nativos do host, um sistema operacional (SO) de multitarefa pode suportar a troca de contexto. Para trocar um executável (identificado por um identificador de contexto de processo [en]) do ambiente de execução, o SO salva seus dados de contexto de execução, como endereços de página de memória e valores de registro. Para trocá-lo de volta, o SO restaura os dados.[1]:[2]
Em um sistema operacional baseado em Linux, um conjunto de dados armazenados em registradores é geralmente salvo em um descritor de processo na memória para implementar uma troca de contexto.[1] PCIDs também são usados.
Ciclo de vida do programa
Um programa nativo do host escrito em uma linguagem diferente de assembly tem fases distintas de ciclo de vida. No tempo de design (design-time), o código-fonte é criado por desenvolvedores de software [en]. No tempo de compilação, o código-fonte é processado em código que é mais prontamente utilizável pelo computador, como código de máquina ou bytecode. No tempo de ligação [en] (link time), um executável é produzido e está pronto para execução.
No tempo de execução (run time, runtime), o código de máquina é executado pela unidade central de processamento (CPU) do computador. O controle começa no ponto de entrada [en] e se move através das instruções do programa de acordo com a lógica do programa e a entrada. O programa roda até que ele termine [en] ou trave.
Carregamento
Quando um programa é iniciado, um carregador [en] realiza a configuração da memória e liga o programa a quaisquer bibliotecas de software vinculadas dinamicamente que ele necessite, e então a execução começa no ponto de entrada [en] do programa. Em alguns casos, uma linguagem ou implementação terá essas tarefas feitas pelo tempo de execução (runtime) da linguagem, embora isso seja incomum em linguagens convencionais em sistemas operacionais de consumo comuns.
Sistema de tempo de execução
Um sistema de tempo de execução (runtime system) é uma camada de software que fornece serviços a um executável; porções de um modelo de execução [en]. Relacionado, um ambiente de tempo de execução (RTE) é tudo com o qual um programa pode interagir; incluindo um sistema de tempo de execução.
A maioria das linguagens de programação inclui um sistema de tempo de execução. Ele pode tratar de questões incluindo gerenciamento de memória, acesso a variáveis, mecanismos de passagem de parâmetros, acesso ao sistema operacional e mais. O compilador faz suposições dependendo do sistema de tempo de execução específico para gerar código. Normalmente, o sistema de tempo de execução tem alguma responsabilidade por configurar e gerenciar a pilha (stack) e o heap, e pode incluir recursos como coleta de lixo, threading ou outros recursos dinâmicos [en] da linguagem.[3]
Ciclo de instrução
O ciclo de instrução é o ciclo que a unidade central de processamento (CPU) segue desde a inicialização até que o computador seja desligado para processar instruções. É composto por três estágios principais: o estágio de busca (fetch), o estágio de decodificação (decode) e o estágio de execução (execute).
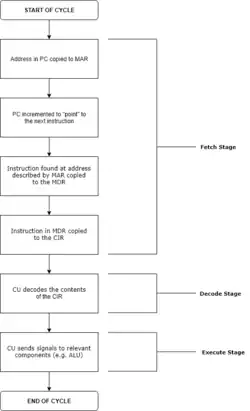
Em CPUs mais simples, o ciclo de instrução é executado sequencialmente, cada instrução sendo processada antes que a próxima seja iniciada. Na maioria das CPUs modernas, os ciclos de instrução são executados simultaneamente, e frequentemente em paralelo, através de um pipeline de instruções: a próxima instrução começa a ser processada antes que a instrução anterior tenha terminado, o que é possível porque o ciclo é dividido em etapas separadas.[4]
Ver também
- Ligação tardia —
- Contador de programa — Registrador da unidade central de processamento
Referências
- ↑ a b Bovet, Daniel P. (2005). Understanding the Linux Kernel. Marco Cesati 3 ed. Sevastopol, CA: O'Reilly. ISBN 0-596-00565-2. OCLC 64549743
- ↑ «Difference between Swapping and Context Switching». GeeksforGeeks (em inglês). 10 de junho de 2021. Consultado em 10 de agosto de 2022
- ↑ Aho, Alfred V.; Lam, Monica Sin-Ling; Sethi, Ravi; Ullman, Jeffrey David (2007). Compilers: Principles, Techniques and Tools
 2nd ed. Boston, MA, US: Pearson Education. p. 427. ISBN 978-0-321-48681-3
2nd ed. Boston, MA, US: Pearson Education. p. 427. ISBN 978-0-321-48681-3
- ↑ Crystal Chen, Greg Novick and Kirk Shimano (2000). «Pipelining». Consultado em 26 de junho de 2019