Kademlia
A Kademlia é uma tabela hash distribuída (DHT) para redes de computadores ponto a ponto descentralizadas projetada por Petar Maymounkov e David Mazières em 2002.[1][2] Ela especifica a estrutura da rede e a troca de informações através de consultas de nós. Os nós Kademlia comunicam-se entre si usando UDP. Uma rede virtual ou rede sobreposta é formada pelos nós participantes. Cada nó é identificado por um número ou ID de nó. O ID de nó serve não apenas como identificação, mas o algoritmo Kademlia usa o ID de nó para localizar valores (geralmente hashes de arquivos ou palavras-chave).
Para procurar o valor associado a uma determinada chave, o algoritmo explora a rede em várias etapas. Cada etapa encontrará nós que estão mais próximos da chave até que o nó contatado retorne o valor ou não sejam encontrados nós mais próximos. Isso é muito eficiente: como muitas outras DHTs, a Kademlia contata apenas nós durante a busca de um total de nós no sistema.


Outras vantagens são encontradas particularmente na estrutura descentralizada, que aumenta a resistência contra um ataque de negação de serviço. Mesmo se todo um conjunto de nós for inundado, isso terá efeito limitado na disponibilidade da rede, uma vez que a rede se recuperará "tricotando" a rede em torno desses "buracos".
A implementação da I2P da Kademlia é modificada para mitigar as vulnerabilidades da Kademlia, como ataques Sybil.[3]
Detalhes do sistema
Redes ponto a ponto são feitas de nós, por design. Os protocolos que esses nós usam para se comunicar e localizar informações tornaram-se mais eficientes ao longo do tempo. As redes de compartilhamento de arquivos ponto a ponto de primeira geração, como o Napster, dependiam de um banco de dados central para coordenar as pesquisas na rede. Redes ponto a ponto de segunda geração, como a Gnutella, usavam inundação (flooding) para localizar arquivos, pesquisando em cada nó da rede. Redes ponto a ponto de terceira geração, como o BitTorrent, usam tabelas hash distribuídas para procurar arquivos na rede. Tabelas hash distribuídas armazenam localizações de recursos em toda a rede.
A Kademlia usa um cálculo de "distância" entre dois nós. Esta distância é calculada como o ou exclusivo (XOR) dos dois IDs de nó, tomando o resultado como um número inteiro sem sinal. Chaves e IDs de nó têm o mesmo formato e comprimento, portanto, a distância pode ser calculada entre eles exatamente da mesma maneira. O ID de nó é tipicamente um grande número aleatório que é escolhido com o objetivo de ser único para um nó específico (veja UUID). Pode acontecer, e acontece, que nós geograficamente distantes – da Alemanha e da Austrália, por exemplo – possam ser "vizinhos" se tiverem escolhido IDs de nó aleatórios semelhantes.
O XOR foi escolhido porque atua como uma função de distância entre todos os IDs de nó. Especificamente:
- a distância entre um nó e ele mesmo é zero
- é simétrica: as "distâncias" calculadas de A para B e de B para A são as mesmas
- segue a desigualdade triangular: dados A, B e C sendo vértices (pontos) de um triângulo, então a distância de A até B é menor do que (ou igual a) a soma da distância de A até C e da distância de C até B.
Essas três condições são suficientes para garantir que o XOR capture todas as características essenciais e importantes de uma função de distância "real", sendo ao mesmo tempo barato e simples de calcular.[1]
Cada iteração de busca na Kademlia aproxima-se um bit do alvo. Um algoritmo de busca Kademlia básico tem complexidade de O(log2 (n)), o que significa que para uma rede com nós, levará no máximo etapas para encontrar esse nó.

Tabelas de roteamento de tamanho fixo
Tabelas de roteamento de tamanho fixo foram apresentadas na versão prévia do artigo original[1] e são usadas na versão posterior apenas para algumas provas matemáticas. Uma implementação real da Kademlia não possui uma tabela de roteamento de tamanho fixo, mas sim uma de tamanho dinâmico.
As tabelas de roteamento Kademlia consistem em uma lista para cada bit do ID do nó (por exemplo, se um ID de nó consiste em 128 bits, um nó manterá 128 dessas listas.). Cada entrada em uma lista contém os dados necessários para localizar outro nó. Os dados em cada entrada da lista são tipicamente o endereço IP, porta e ID de nó de outro nó. Cada lista corresponde a uma distância específica do nó. Nós que podem ir para a n-ésima lista devem ter um n-ésimo bit diferente do ID do nó; os primeiros n-1 bits do ID candidato devem corresponder aos do ID do nó. Isso significa que é muito fácil preencher a primeira lista, pois 1/2 dos nós na rede são candidatos distantes. A próxima lista pode usar apenas 1/4 dos nós na rede (um bit mais próximo que a primeira), etc.
Com um ID de 128 bits, cada nó na rede classificará outros nós em uma das 128 distâncias diferentes, uma distância específica por bit.
À medida que os nós são encontrados na rede, eles são adicionados às listas. Isso inclui operações de armazenamento e recuperação e até mesmo ajudar outros nós a encontrar uma chave. Todo nó encontrado será considerado para inclusão nas listas. Portanto, o conhecimento que um nó tem da rede é muito dinâmico. Isso mantém a rede constantemente atualizada e adiciona resiliência a falhas ou ataques.
Na literatura da Kademlia, as listas são referidas como k-buckets (baldes-k). k é um número definido para todo o sistema, como 20. Cada k-bucket é uma lista contendo até k entradas dentro; ou seja, para uma rede com k=20, cada nó terá listas contendo até 20 nós para um determinado bit (uma determinada distância de si mesmo).
Como os possíveis nós para cada k-bucket diminuem rapidamente (porque haverá muito poucos nós que estão tão próximos), os k-buckets de bits inferiores mapearão totalmente todos os nós nessa seção da rede. Como a quantidade de IDs possíveis é muito maior do que qualquer população de nós jamais poderá ser, alguns dos k-buckets correspondentes a distâncias muito curtas permanecerão vazios.
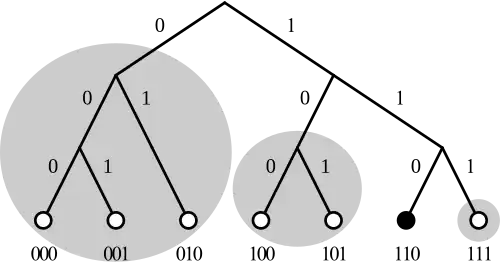
Considere a rede simples à direita. O tamanho da rede é 2^3 ou oito chaves e nós no máximo. Existem sete nós participando; os pequenos círculos na parte inferior. O nó em consideração é o nó seis (binário 110) em preto. Existem três k-buckets para cada nó nesta rede. Os nós zero, um e dois (binário 000, 001 e 010) são candidatos para o k-bucket mais distante. O nó três (binário 011, não mostrado) não está participando da rede. No k-bucket do meio, os nós quatro e cinco (binário 100 e 101) são colocados. Finalmente, o terceiro k-bucket pode conter apenas o nó sete (binário 111). Cada um dos três k-buckets está fechado em um círculo cinza. Se o tamanho do k-bucket fosse dois, então o 2-bucket mais distante poderia conter apenas dois dos três nós. Por exemplo, se o nó seis tem o nó um e dois no 2-bucket mais distante, ele teria que solicitar uma busca de ID de nó a esses nós para encontrar a localização (endereço ip) do nó zero. Cada nó conhece bem sua vizinhança e tem contato com alguns nós distantes que podem ajudar a localizar outros nós distantes.
Sabe-se que os nós que estiveram conectados por um longo tempo em uma rede provavelmente permanecerão conectados por um longo tempo no futuro.[4][5] Devido a essa distribuição estatística, a Kademlia seleciona nós conectados há muito tempo para permanecerem armazenados nos k-buckets. Isso aumenta o número de nós válidos conhecidos em algum momento no futuro e fornece uma rede mais estável.
Quando um k-bucket está cheio e um novo nó é descoberto para esse k-bucket, o nó visto menos recentemente no k-bucket recebe um PING. Se o nó for encontrado ainda vivo, o novo nó é colocado em uma lista secundária, um cache de substituição. O cache de substituição é usado apenas se um nó no k-bucket parar de responder. Em outras palavras: novos nós são usados apenas quando os nós mais antigos desaparecem.
Mensagens de protocolo
A Kademlia possui quatro mensagens.
- PING — Usada para verificar se um nó ainda está vivo.
- STORE — Armazena um par (chave, valor) em um nó.
- FIND_NODE — O destinatário da solicitação retornará os k nós em seus próprios buckets que são os mais próximos da chave solicitada.
- FIND_VALUE — O mesmo que FIND_NODE, mas se o destinatário da solicitação tiver a chave solicitada em seu armazenamento, ele retornará o valor correspondente.
Cada mensagem RPC inclui um valor aleatório do iniciador. Isso garante que, quando a resposta for recebida, ela corresponda à solicitação enviada anteriormente (veja magic cookie [en]).
Localizando nós
As buscas de nós podem prosseguir de forma assíncrona. A quantidade de buscas simultâneas é denotada por α e é tipicamente três. Um nó inicia uma solicitação FIND_NODE consultando os α nós em seus próprios k-buckets que são os mais próximos da chave desejada. Quando esses nós destinatários recebem a solicitação, eles olham em seus k-buckets e retornam os k nós mais próximos da chave desejada que eles conhecem. O solicitante atualizará uma lista de resultados com os resultados (IDs de nó) que recebe, mantendo os k melhores (os k nós que estão mais próximos da chave pesquisada) que respondem às consultas. Então, o solicitante selecionará esses k melhores resultados e emitirá a solicitação para eles, e iterará esse processo repetidamente. Como cada nó tem um conhecimento melhor de seus próprios arredores do que qualquer outro nó, os resultados recebidos serão outros nós que estão cada vez mais próximos da chave pesquisada. As iterações continuam até que não sejam retornados nós que sejam mais próximos do que os melhores resultados anteriores. Quando as iterações param, os melhores k nós na lista de resultados são aqueles em toda a rede que estão mais próximos da chave desejada.
A informação do nó pode ser aumentada com tempos de ida e volta, ou RTT. Esta informação será usada para escolher um tempo limite (time-out) específico para cada nó consultado. Quando uma consulta atinge o tempo limite, outra consulta pode ser iniciada, nunca ultrapassando α consultas ao mesmo tempo.
Localizando recursos
A informação é localizada mapeando-a para uma chave. Um hash é tipicamente usado para o mapa. Os nós armazenadores terão informações devido a uma mensagem STORE anterior. A localização de um valor segue o mesmo procedimento que a localização dos nós mais próximos de uma chave, exceto que a busca termina quando um nó tem o valor solicitado em seu armazenamento e retorna esse valor.
Os valores são armazenados em vários nós (k deles) para permitir que os nós entrem e saiam e ainda tenham o valor disponível em algum nó. Periodicamente, um nó que armazena um valor explorará a rede para encontrar os k nós que estão próximos do valor da chave e replicará o valor neles. Isso compensa os nós desaparecidos.
Além disso, para valores populares que podem ter muitas solicitações, a carga nos nós armazenadores é diminuída fazendo com que um recuperador armazene esse valor em algum nó próximo, mas fora dos k mais próximos. Esse novo armazenamento é chamado de cache. Desta forma, o valor é armazenado cada vez mais longe da chave, dependendo da quantidade de solicitações. Isso permite que buscas populares encontrem um armazenador mais rapidamente. Como o valor é retornado de nós mais distantes da chave, isso alivia possíveis "pontos quentes" (hot spots). Os nós de cache descartarão o valor após um certo tempo, dependendo de sua distância da chave.
Algumas implementações (por exemplo, Rede Kad) não têm nem replicação nem cache. O objetivo disso é remover informações antigas rapidamente do sistema. O nó que está fornecendo o arquivo atualizará periodicamente as informações na rede (executará mensagens FIND_NODE e STORE). Quando todos os nós que possuem o arquivo ficarem offline, ninguém estará atualizando seus valores (fontes e palavras-chave) e a informação eventualmente desaparecerá da rede.
Entrando na rede
Um nó que gostaria de se juntar à rede deve primeiro passar por um processo de inicialização [en] (bootstrap). Nesta fase, o nó que está entrando precisa saber o endereço IP e a porta de outro nó — um nó de inicialização (obtido do usuário ou de uma lista armazenada) — que já está participando da rede Kademlia. Se o nó que está entrando ainda não participou da rede, ele calcula um número de ID aleatório, que em virtude de ser um número aleatório muito grande é extremamente provável que não esteja já atribuído a qualquer outro nó. Ele usa esse ID até sair da rede.
O nó ingressante insere o nó de inicialização em um de seus k-buckets. O nó ingressante então realiza uma busca de nó de seu próprio ID contra o nó de inicialização (o único outro nó que ele conhece). A "auto-busca" preencherá os k-buckets de outros nós com o novo ID do nó e preencherá os k-buckets do nó ingressante com os nós no caminho entre ele e o nó de inicialização. Depois disso, o nó ingressante atualiza todos os k-buckets mais distantes do que o k-bucket em que o nó de inicialização cai. Essa atualização é apenas uma busca de uma chave aleatória que está dentro desse intervalo do k-bucket.
Inicialmente, os nós têm um k-bucket. Quando o k-bucket fica cheio, ele pode ser dividido. A divisão ocorre se o intervalo de nós no k-bucket abrange o próprio id do nó (valores à esquerda e à direita em uma árvore binária). A Kademlia relaxa até mesmo esta regra para o k-bucket dos "nós mais próximos", porque tipicamente um único bucket corresponderá à distância onde todos os nós que são os mais próximos deste nó estão, eles podem ser mais do que k, e queremos que ele conheça todos eles. Pode acontecer que uma subárvore binária altamente desequilibrada exista perto do nó. Se k for 20, e houver mais de 21 nós com um prefixo "xxx0011....." e o novo nó for "xxx000011001", o novo nó pode conter múltiplos k-buckets para os outros 21+ nós. Isso é para garantir que a rede saiba sobre todos os nós na região mais próxima.
Buscas aceleradas
A Kademlia usa uma métrica XOR para definir a distância. Dois IDs de nó ou um ID de nó e uma chave sofrem XOR e o resultado é a distância entre eles. Para cada bit, a função XOR retorna zero se os dois bits forem iguais e um se os dois bits forem diferentes. As distâncias na métrica XOR satisfazem a desigualdade triangular: dados A, B e C sendo vértices (pontos) de um triângulo, então a distância de A até B é menor do que (ou igual a) a soma das distâncias de A até C e de C até B.
A métrica XOR permite que a Kademlia estenda as tabelas de roteamento além de bits únicos. Grupos de bits podem ser colocados em k-buckets. O grupo de bits é denominado prefixo. Para um prefixo de m-bits, haverá 2m-1 k-buckets. O k-bucket ausente é uma extensão adicional da árvore de roteamento que contém o ID do nó. Um prefixo de m-bits reduz o número máximo de buscas de log2 n para log2m n. Estes são valores máximos e o valor médio será muito menor, aumentando a chance de encontrar um nó em um k-bucket que compartilha mais bits do que apenas o prefixo com a chave alvo.
Os nós podem usar misturas de prefixos em sua tabela de roteamento, como a Rede Kad usada pelo eMule. [carece de fontes] A rede Kademlia poderia até ser heterogênea em implementações de tabela de roteamento, à custa de complicar a análise de buscas.
Significância acadêmica
Embora a métrica XOR não seja necessária para entender a Kademlia, ela é crítica na análise do protocolo. A aritmética XOR forma um grupo abeliano permitindo uma análise fechada. Outros protocolos e algoritmos DHT requerem simulação ou análise formal complicada para prever o comportamento e a correção da rede. O uso de grupos de bits como informações de roteamento também simplifica os algoritmos.
Análise matemática do algoritmo
Para analisar o algoritmo, considere uma rede Kademlia de nós com IDs , cada um dos quais é uma string de comprimento que consiste apenas em uns e zeros. Ela pode ser modelada como uma trie, na qual cada folha representa um nó, e o caminho rotulado da raiz até uma folha representa seu ID. Para um nó , seja o conjunto de nós (IDs) que compartilham um prefixo com de comprimento . Então, o preenchimento do -ésimo bucket de pode ser modelado como a adição de ponteiros da folha para folhas (IDs) escolhidas uniformemente ao acaso de . Assim, o roteamento pode ser visto como saltar entre as folhas ao longo desses ponteiros de modo que cada passo vá em direção ao ID alvo tanto quanto possível, ou seja, de uma forma gulosa.








Seja o número de saltos necessários para ir da folha para um ID alvo . Assumindo que são escolhidos deterministicamente de , foi provado que



![{\displaystyle \sup _{x_{1},\ldots ,x_{n}}\,\sup _{x\in \{x_{1},\ldots ,x_{n}\}}\,\sup _{y\in \{0,1\}^{d}}\mathbb {E} [T_{xy}]\leq (1+o(1)){\frac {\log n}{H_{k}}},}](./_assets_/eb734a37dd21ce173a46342d1cc64c92/45c858fed0fa63cee23b58ab815118ac52bac762.svg)
onde é o -ésimo número harmônico [en]. Uma vez que quando , quando é grande é limitado superiormente por cerca de , independentemente de como os IDs e o alvo são escolhidos.[6] Isso justifica a intuição de que na Kademlia apenas nós são contatados na busca por um nó alvo.





Para tornar o modelo mais próximo das redes Kademlia reais, também podem ser assumidos como escolhidos uniformemente ao acaso sem reposição de . Então pode ser provado que para todo e ,

![{\displaystyle {\begin{aligned}&T_{xy}\xrightarrow {p} {\frac {\log n}{c_{k}}},\\&\mathbb {E} [T_{xy}]\to {\frac {\log n}{c_{k}}},\end{aligned}}}](./_assets_/eb734a37dd21ce173a46342d1cc64c92/8969828abb25d0d320d069d57b607e60dbaec030.svg)
onde é uma constante dependendo apenas de com quando . Assim, para grande, converge para uma constante próxima de . Isso implica que o número de nós que precisam ser contatados na busca por um nó alvo é, na verdade, em média.[7]





Uso em redes de compartilhamento de arquivos
A Kademlia é usada em redes de compartilhamento de arquivos. Ao fazer pesquisas por palavras-chave na Kademlia, pode-se encontrar informações na rede de compartilhamento de arquivos para que possam ser baixadas. Como não há uma instância central para armazenar um índice de arquivos existentes, essa tarefa é dividida igualmente entre todos os clientes: se um nó deseja compartilhar um arquivo, ele processa o conteúdo do arquivo, calculando a partir dele um número (hash) que identificará esse arquivo dentro da rede de compartilhamento de arquivos. Como os hashes de arquivos e os IDs de nó têm o mesmo comprimento, o cliente pode usar a função de distância XOR para procurar vários nós cujo ID esteja próximo do hash e instruir esses nós a armazenar o endereço IP do publicador de uma maneira definida pela implementação. Os nós com IDs mais próximos do hash do arquivo terão, portanto, uma lista de endereços IP de pares/publicadores desse arquivo, dos quais um cliente pode, de maneira definida pela implementação, baixar o arquivo.
Os clientes que desejam baixar o arquivo deste publicador não precisam saber o endereço IP do publicador (pode haver muitos publicadores), mas apenas o hash do arquivo. Um cliente pesquisador usará a Kademlia para pesquisar na rede o nó cujo ID tem a menor distância para o hash do arquivo e, em seguida, recuperará a lista de fontes que está armazenada nesse nó.
Como uma chave pode corresponder a muitos valores, por exemplo, muitas fontes do mesmo arquivo, cada nó de armazenamento pode ter informações diferentes. Então, as fontes são solicitadas de todos os k nós próximos à chave, sendo k o tamanho do bucket.
O hash do arquivo é geralmente obtido de um link magnético da Internet especialmente formado encontrado em outro lugar, ou incluído em um arquivo de indexação obtido de outras fontes.
Pesquisas de nome de arquivo são implementadas usando palavras-chave. O nome do arquivo é dividido em suas palavras constituintes. Cada uma dessas palavras-chave é transformada em hash e armazenada na rede, juntamente com o nome do arquivo e o hash do arquivo correspondentes. Uma pesquisa envolve escolher uma das palavras-chave, contatar o nó com um ID mais próximo desse hash de palavra-chave e recuperar a lista de nomes de arquivos que contêm a palavra-chave. Como cada nome de arquivo na lista tem seu hash anexado, o arquivo escolhido pode então ser obtido da maneira normal.
Implementações
Redes
Redes públicas que usam o algoritmo Kademlia (essas redes são incompatíveis umas com as outras):
- I2P: uma camada de rede sobreposta anônima.[8]
- Rede Kad: desenvolvida originalmente pela comunidade eMule para substituir a arquitetura baseada em servidor da rede eDonkey [en].
- Ethereum: o protocolo de descoberta de nós na pilha de rede blockchain Ethereum é baseado em uma implementação modificada da Kademlia. Ele não usa a porção de valor, tem verificação mútua de endpoint, permite encontrar todos os nós na distância logarítmica especificada, tem uma diferenciação de subprotocolos.[9]
- Overnet: Com KadC, uma biblioteca C para lidar com sua Kademlia está disponível. (o desenvolvimento da Overnet foi descontinuado)
- Mainline DHT [en]: uma DHT para BitTorrent baseada em uma implementação do algoritmo Kademlia, para torrents sem rastreador (trackerless).
- Osiris [en] (todas as versões): usado para gerenciar portais web distribuídos e anônimos.
- Retroshare: plataforma de comunicação descentralizada F2F com VOIP seguro, mensagens instantâneas, transferência de arquivos, etc.
- Tox: uma plataforma de mensagens, VoIP e chat de vídeo totalmente distribuída
- Gnutella DHT: originalmente pela LimeWire[10][11] para aumentar o protocolo Gnutella para encontrar locais de arquivos alternativos, agora em uso por outros clientes gnutella.[12]
- IPFS: um sistema de arquivos distribuído ponto a ponto baseado em libp2p [en].[13]
- TeleHash [en]: um protocolo de rede mesh que usa Kademlia para resolver conexões diretas entre as partes.[14]
- iMule: software utilitário de compartilhamento de arquivos para I2P.
- OpenDHT [en]: biblioteca que fornece uma implementação da Kademlia, usada pelo Jami [en] e outros.[15]
- GNUnet [en]: pilha de rede alternativa para construir aplicativos distribuídos seguros, descentralizados e que preservam a privacidade. Usa uma versão aleatória da Kademlia chamada R5N.[16]
- Dat [en]: uma ferramenta de compartilhamento de arquivos ponto a ponto baseada[carece de fontes] no Protocolo Hypercore.[17]
Ver também
- Chord
- Koorde [en]
- Pastry (DHT) [en]
- Rede endereçável por conteúdo [en]
- Tapestry (DHT)
Referências
- ↑ a b c Maymounkov, Petar; Mazieres, David. «Kademlia: A Peer-to-peer Information System Based on the XOR Metric» (PDF). pdos.csail.mit.edu. Consultado em 28 de dezembro de 2023
- ↑ «Papers by David Mazières». www.scs.stanford.edu
- ↑ «The Network Database - I2P». geti2p.net
- ↑ Stefan Saroiu, P. Krishna Gummadi and Steven D. Gribble. A Measurement Study of Peer-to-Peer File Sharing Systems. Technical Report UW-CSE-01-06-02, University of Washington, Department of Computer Science and Engineering, July 2001.
- ↑ Daniel Stutzbach and Reza Rejaie. Understanding Churn in Peer-to-Peer Networks Section 5.5 Uptime Predictability, Internet Measurement Conference, Rio de Janeiro, October, 2006.
- ↑ Cai, X. S.; Devroye, L. (2013). «A Probabilistic Analysis of Kademlia Networks». Algorithms and Computation. Col: Lecture Notes in Computer Science. 8283. [S.l.: s.n.] pp. 711–721. ISBN 978-3-642-45029-7. arXiv:1309.5866
 . doi:10.1007/978-3-642-45030-3_66
. doi:10.1007/978-3-642-45030-3_66
- ↑ Cai, Xing Shi; Devroye, Luc (2015). «The Analysis of Kademlia for Random IDs». Internet Mathematics. 11 (6): 1–16. ISSN 1542-7951. arXiv:1402.1191. doi:10.1080/15427951.2015.1051674
- ↑ «Intro - I2P». geti2p.net
- ↑ «From Kademlia to Discv5». 20 de janeiro de 2025 – via GitHub
- ↑ «Slyck News - LimeWire Regains Top Download.com Position». www.slyck.com. Consultado em 20 de junho de 2007. Arquivado do original em 19 de janeiro de 2019
- ↑ «Mojito - LimeWire». wiki.limewire.org. Cópia arquivada em 17 de fevereiro de 2009
- ↑ «Gtk-gnutella changelog». sourceforge.net. Consultado em 23 de janeiro de 2010. Arquivado do original em 23 de julho de 2011
- ↑ «IPFS Paper» (PDF). GitHub
- ↑ «#7: Jeremie Miller - TeleHash». Consultado em 12 de março de 2016
- ↑ «Home». OpenDHT Wiki. GitHub. Savoir-faire Linux. Consultado em 19 de março de 2021
- ↑ «R5N: Randomized Recursive Routing for Restricted-Route Networks» (PDF)
- ↑ «Hypercore Protocol». Consultado em 27 de dezembro de 2020. Arquivado do original em 23 de dezembro de 2020